






https://github.com/rayleizhu/BiFormer
实验结果
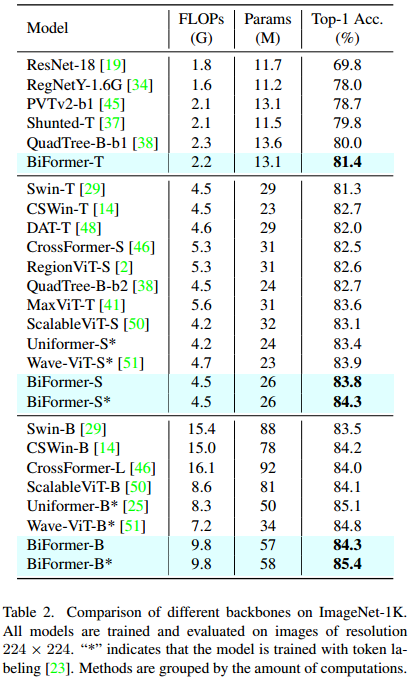
ImageNet1k:图像分类,实例分割,目标检测
ADE20K:语义分割
图像分类参数设置
input img:224*224
300epochs
AdamW 优化器 权重衰减0.05
初始学习率0.001
5个预热
batch size:1024
正则化技术:RandAugment (rand-m9-mstd0.5inc1)、MixUp (prob = 0:8)、CutMix (prob = 1:0)、Random erase (prob = 0:25)和Random depth(分别为BiFormer-T/S/B, prob =0:1 =0:15=0:4)。
目标检测和实例分割
使用MMDetection提供的标准1x时间表(12个epoch)进行训练,
使用的是AdamW优化器,而不是SGD。
使用初始学习率为1e−4,
批大小为16,
而对于RetinaNet和Mask R-CNN,权值衰减分别设置为1e−4和5e−2。
在训练过程中,调整输入图像的大小,将较短的一面固定为800像素,同时保持较长的一面不超过1333像素
主要关注目标检测
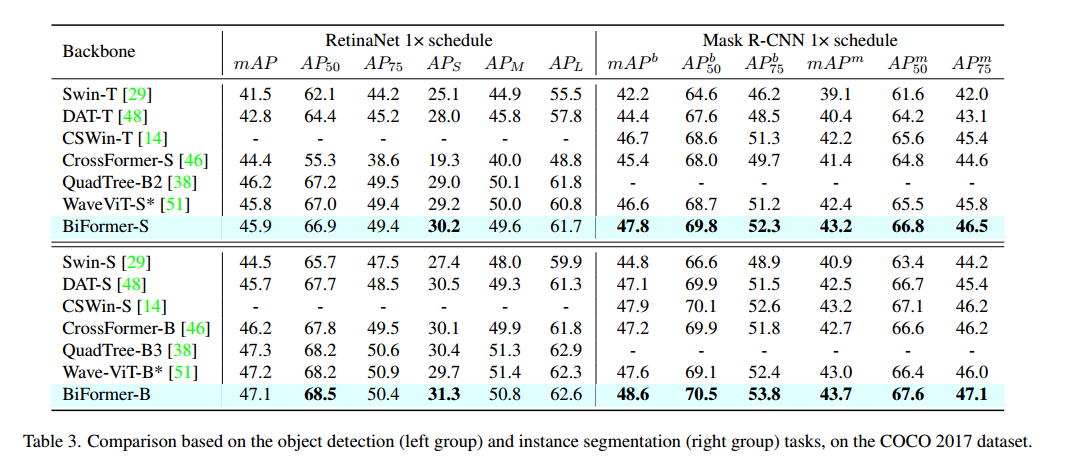
Ablation Study
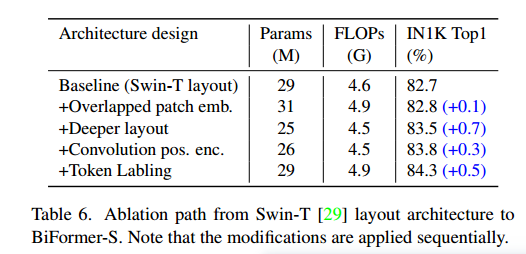
Visualization of Attention Map

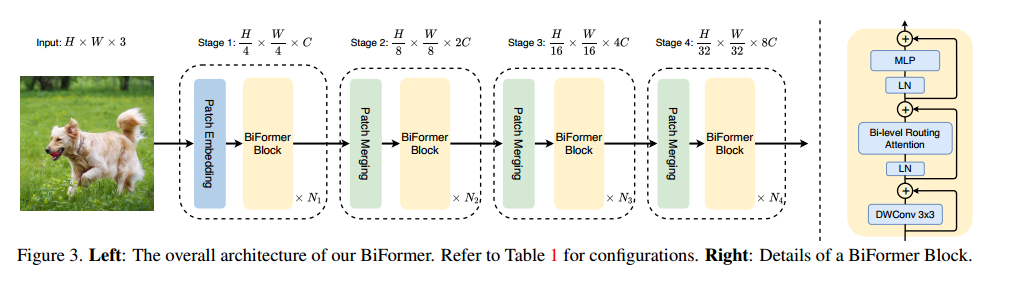
方法
Bi-Level Routing Attention (BRA)
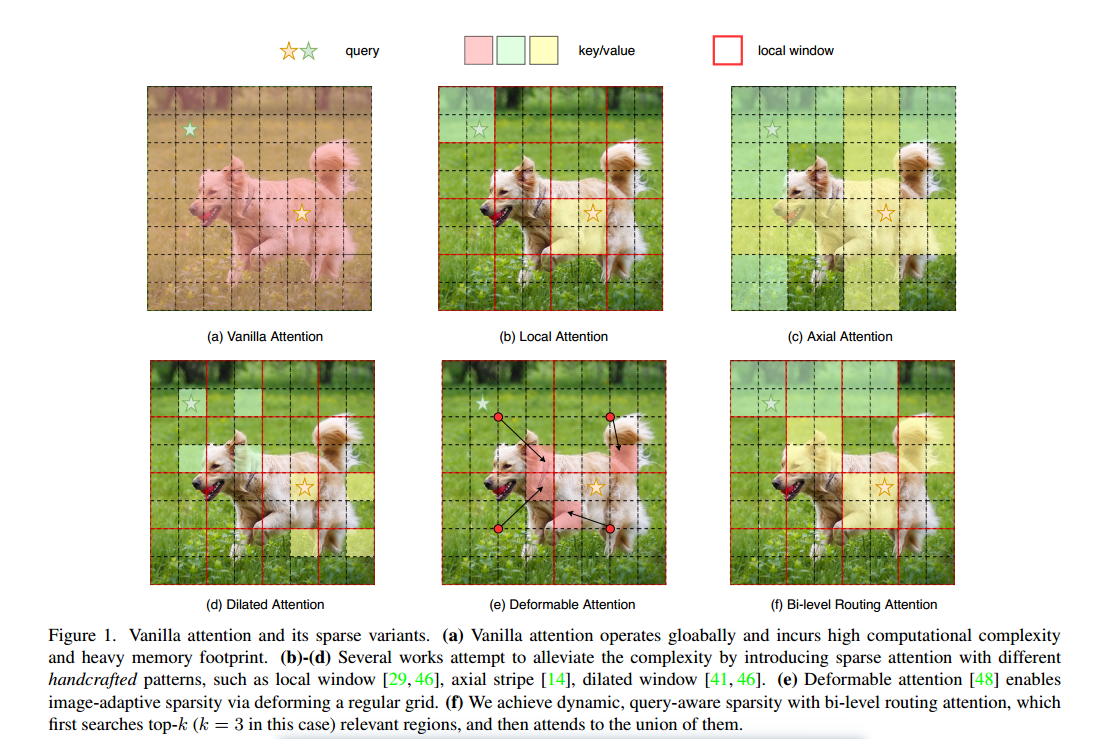
原来的方法要么使用手工制作的静态模式,要么在所有查询中共享键值对的抽样子集

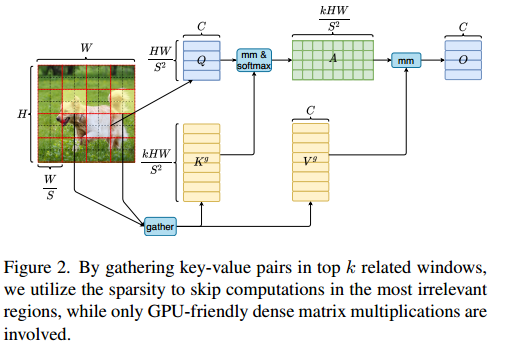
Region partition and input projection.
首先对输入的的图片分到的不重叠区域
每一块区域就变成了
同时输入的X重构成
然后使用线性函数分成Q、K、V三部分。
Region-to-region routing with directed graph
对Q和K进行取平均值处理,然后和矩阵相乘。
然后对某一区域取前k个对它影响最大的区域,即为。
Token-to-token attention.
对K和V中的进行合并为和,然后进行。
LCE是局部增强分支,其中LCE被设置成DWC即深度卷积,内核为5。
Complexity Analysis of BRA
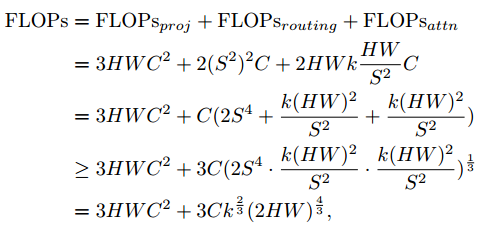
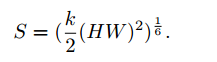


结构设计
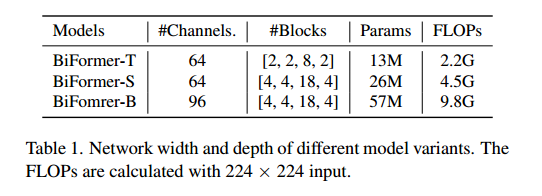
Q.E.D.