






介绍两篇论文
Slender Object Detection: Diagnoses and Improvements-CVPR2020
https://github.com/wanzysky/SlenderObjDet/tree/master
https://arxiv.org/abs/2011.08529
https://ar5iv.labs.arxiv.org/html/2011.08529
slender object的三种情况
- 物体本身的细长
- 由于遮挡导致
- 不同角度看到
数据集使用
COCO+Objects365组成COCO+数据集,其中objects365主要是为了中和COCO数据集中slender数据的较少问题,COCO+中slender数据是COCO的8倍。
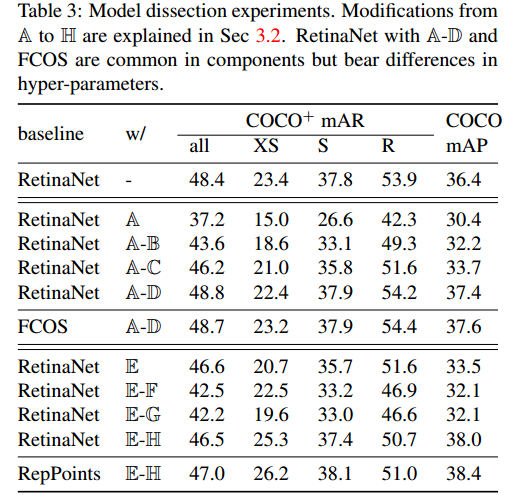
实验结果
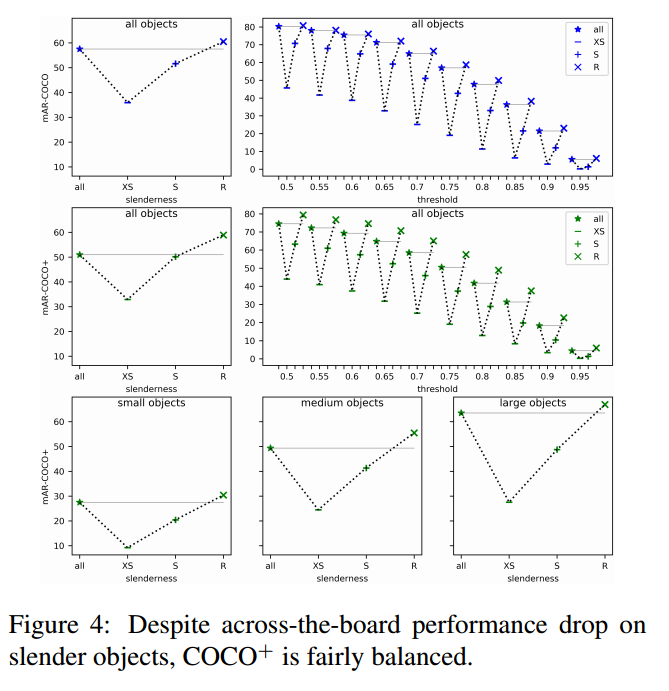
验证的实验结果,使用的指标是MAR
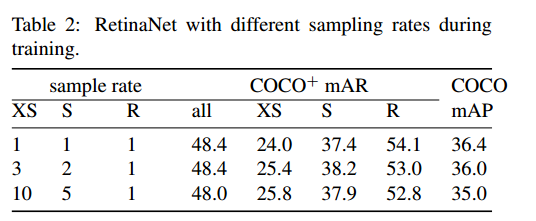
采样率的差异性
模型解剖阶段
有锚点和无锚点
边界框和点集
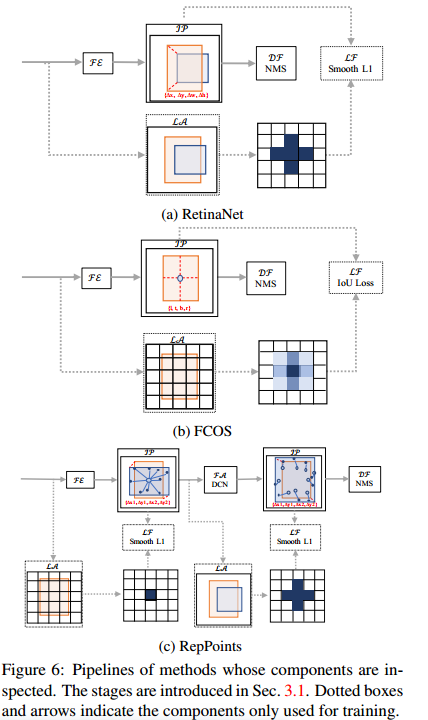
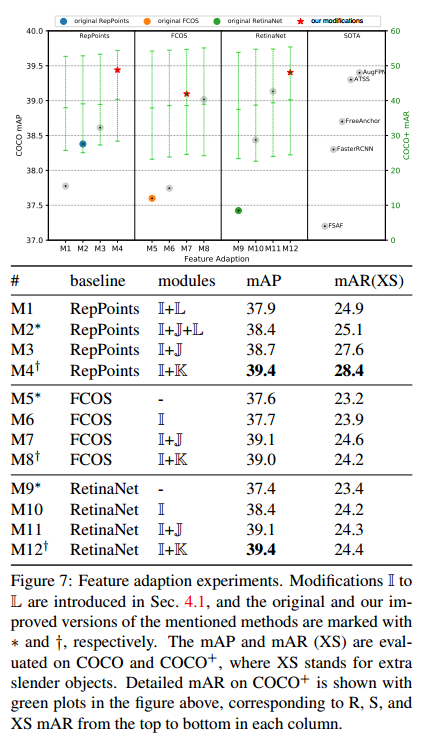
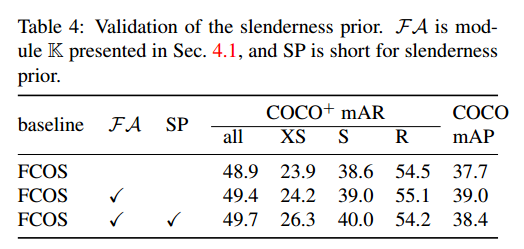
Improving Slender Object Detection(重点)
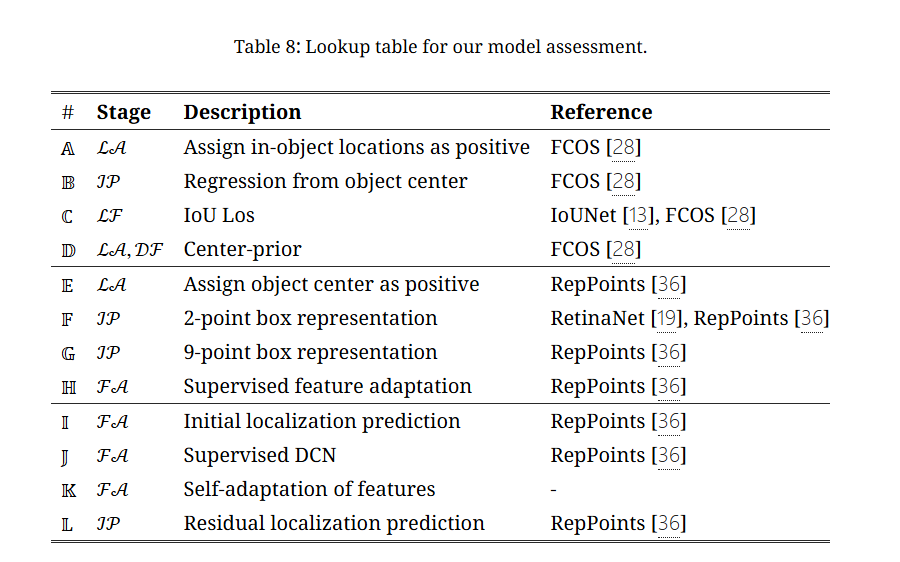
自适应特征

中心点
其中l,r,t,b分别是边界框左右上下边界。
在几何均值下,细长物体的长边衰减较慢,短边衰减较快,导致定位细长物体的训练不足。自然地,将公式扩展到 以下内容:
s是物体的slenderness。
2-point and 9-point
2-point表示物体的简单表示方式,通常指物体的对角线顶点。对于标准的边界框(bounding box),可以用左上角和右下角两个顶点来定义一个矩形。这种表示方式在检测常规物体时非常普遍,因为它简单且计算效率高。
9-point表示更加细化的物体表示方式,通常在纤细物体检测中使用。这种方法不仅考虑边界框的四个顶点,还引入了中点的概念。例如,一个矩形边界框可以由9个点来描述:四个顶点、四个边的中点,以及中心点。这种细化表示可以帮助更准确地描述和定位形状不规则或纤细的物体,因为它能捕捉到更多的形状信息。
code demo
DFAM-DETR: Deformable feature based attention mechanism DETR on slender object detection-CVPR2022
暂时没有github。
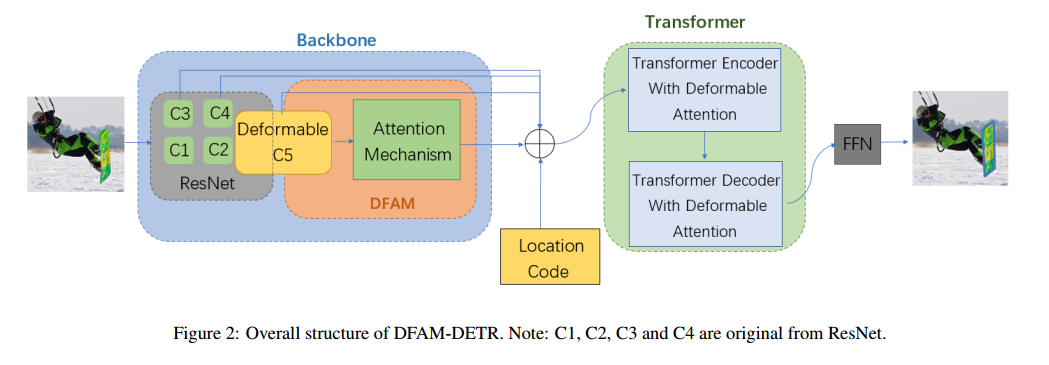
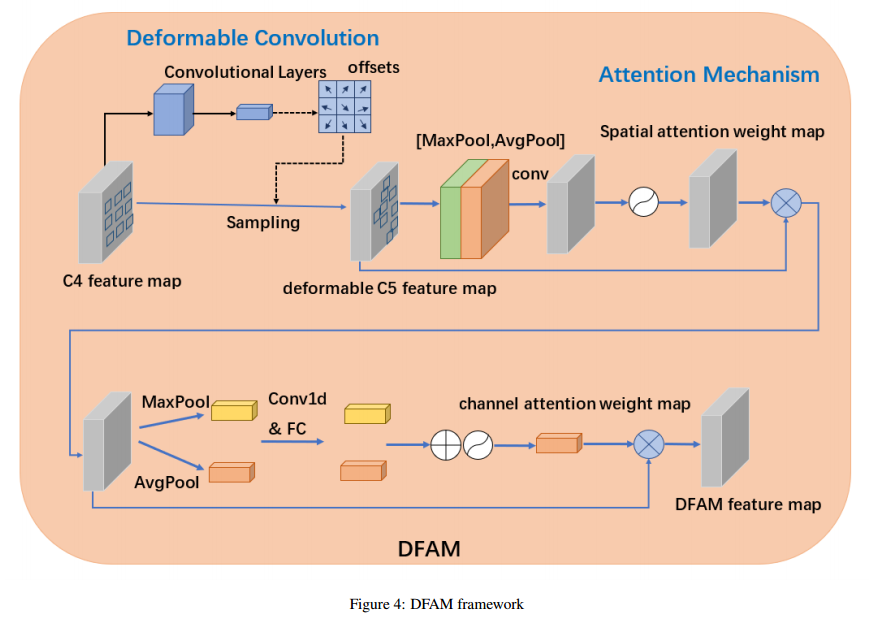
Q.E.D.