






Paper: https://arxiv.org/abs/2304.08069
Code: https://github.com/lyuwenyu/RT-DETR
DETR的几大缺点
- 训练收敛速度慢
- 计算成本高
- 查询难以优化
已有的部分变体进行的改善
加速收敛
Deformable-DETR:通过提高注意机制的效率,加速多尺度特征的训练收敛。
DAB-DETR and DN-DETR: 通过引入迭代改进方案和去噪训练进一步提高性能。
Group-DETR: 引入分组式一对多分配。
降低计算成本
Efficient DETR and Sparse DETR: 通过减少编码器和解码器层的数量或更新查询的数量来降低计算成本。
Lite DETR: 以交错的方式降低底层特征的更新频率,提高编码器的效率。
优化查询初始化
Conditional DETR and Anchor DETR: 降低查询的优化难度
NMS分析
采用的是efficientNMSPlugin、EfficientNMSFilter、RadixSort三个插件的采用的是efficientNMSPlugin。
https://github.com/NVIDIA/TensorRT/tree/release/8.6/plugin/efficientNMSPlugin
efficientNMSPlugin
用途:高效非极大值抑制(NMS)插件,通常用于目标检测模型中去除多余的边界框。
工作原理:该插件通过快速筛选掉得分较低或重叠度较高的边界框,只保留最优的检测结果,从而提高模型的预测精度和效率。
EfficientNMSFilter
用途:进一步优化和过滤边界框的插件,通常配合 EfficientNMSPlugin 使用。
工作原理:在非极大值抑制后,对边界框进行更细致的过滤和处理,以确保最终输出的边界框更加准确和符合实际需求。
RadixSort
用途:一种高效的排序算法,常用于需要对大量数据进行快速排序的场景。
工作原理:基数排序通过逐位对数字进行排序,通常从最低有效位开始,到最高有效位结束,利用计数排序(Counting Sort)或桶排序(Bucket Sort)等辅助算法来实现。
EfficientNMS
用途:执行核心的非极大值抑制操作。
功能:在排序好的边界框中,移除重叠度较高且得分较低的边界框,只保留最优的检测结果。
工作原理
排序(RadixSort):首先使用 RadixSort 内核对所有边界框按照得分进行排序。排序确保得分最高的边界框优先处理。
过滤(EfficientNMSFilter):使用 EfficientNMSFilter 内核对排序后的边界框进行初步过滤,去除得分较低的边界框。
非极大值抑制(EfficientNMS):使用 EfficientNMS 内核对过滤后的边界框进行非极大值抑制,移除重叠度较高的边界框,只保留最优的边界框。
模型设计
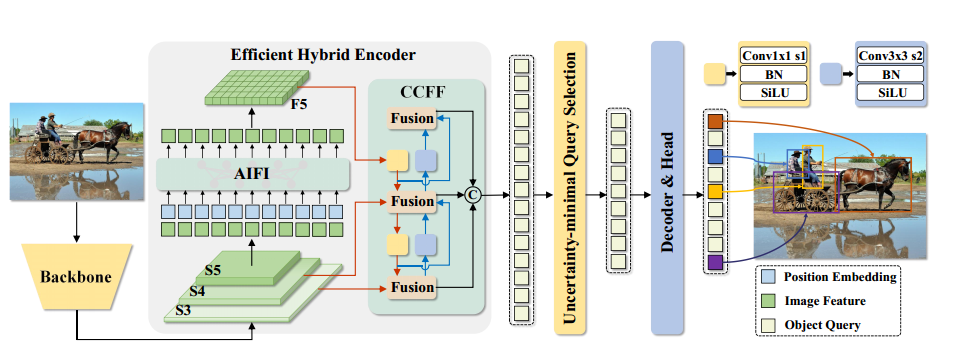
RT-DETR由主干、高效混合编码器和带辅助预测头的变压器解码器组成。
AIFI-CCFF设计思路
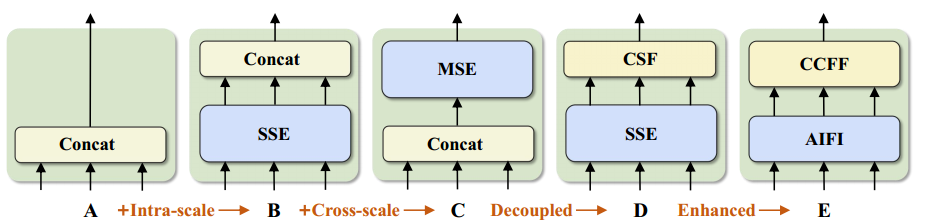
AIFI模块
就是把原来对三个的Transformer编码器改成了对高维特征进行的编码。
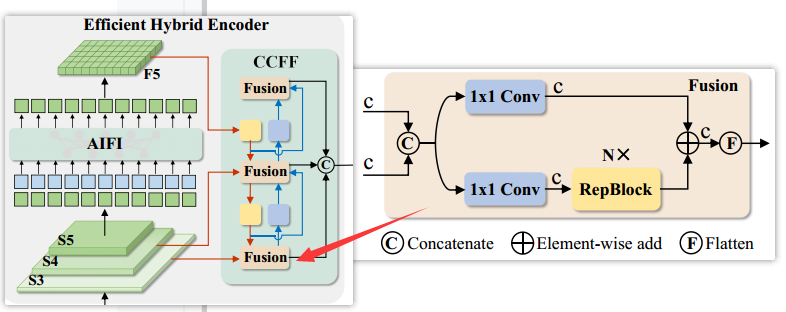
CCFF模块
所谓的CCFM其实还是PaFPN(Feature Pyramid Networks for Object Detection),其中的Fusion模块就是一个CSPBlock(A New Backbone that can Enhance Learning Capability of CNN)风格的模块。
DINO-R50
单尺度SSE
import torch
import torch.nn as nn
class SingleScaleTransformer(nn.Module):
def __init__(self, in_channels, out_channels, num_heads, num_layers):
super(SingleScaleTransformer, self).__init__()
self.proj_layer = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.transformer_encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=out_channels, nhead=num_heads),
num_layers=num_layers
)
self.position_encoding = nn.Parameter(torch.randn(1, 1000, out_channels))
def forward(self, feature):
# feature: Single scale feature map
projected_feature = self.proj_layer(feature).flatten(2).permute(0, 2, 1)
# Add position encoding
projected_feature += self.position_encoding[:, :projected_feature.size(1), :]
# Apply Transformer Encoder
transformed_feature = self.transformer_encoder(projected_feature.permute(1, 0, 2)).permute(1, 0, 2)
return transformed_feature
# Example usage:
feature = torch.randn(2, 256, 32, 32) # Single scale feature map
model = SingleScaleTransformer(in_channels=256, out_channels=256, num_heads=8, num_layers=6)
output = model(feature)
print(output.shape)
多尺度MSE
import torch
import torch.nn as nn
class MultiScaleTransformer(nn.Module):
def __init__(self, in_channels_list, out_channels, num_heads, num_layers):
super(MultiScaleTransformer, self).__init__()
self.proj_layers = nn.ModuleList([
nn.Conv2d(in_channels, out_channels, kernel_size=1)
for in_channels in in_channels_list
])
self.transformer_encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=out_channels, nhead=num_heads),
num_layers=num_layers
)
self.position_encoding = nn.Parameter(torch.randn(1, 1000, out_channels))
def forward(self, features):
# features: List of multi-scale feature maps
proj_features = [proj_layer(f).flatten(2).permute(0, 2, 1) for proj_layer, f in zip(self.proj_layers, features)]
concatenated_features = torch.cat(proj_features, dim=1)
# Add position encoding
concatenated_features += self.position_encoding[:, :concatenated_features.size(1), :]
# Apply Transformer Encoder
transformed_features = self.transformer_encoder(concatenated_features.permute(1, 0, 2)).permute(1, 0, 2)
return transformed_features
# Example usage:
features = [torch.randn(2, 256, 32, 32), torch.randn(2, 512, 16, 16), torch.randn(2, 1024, 8, 8)]
model = MultiScaleTransformer(in_channels_list=[256, 512, 1024], out_channels=256, num_heads=8, num_layers=6)
output = model(features)
print(output.shape)
实验结果

对于这个内容,证明了两件事。
- Transformer的Encoder部分只需要处理high-level特征,既能大幅度削减计算量、提升计算速度,同时也不会损伤到性能,甚至还有所提升
- 对于多尺度特征的交互和融合,我们仍可以采用CNN架构常用的PAN网络来搭建,只需要一些细节上的调整即可。
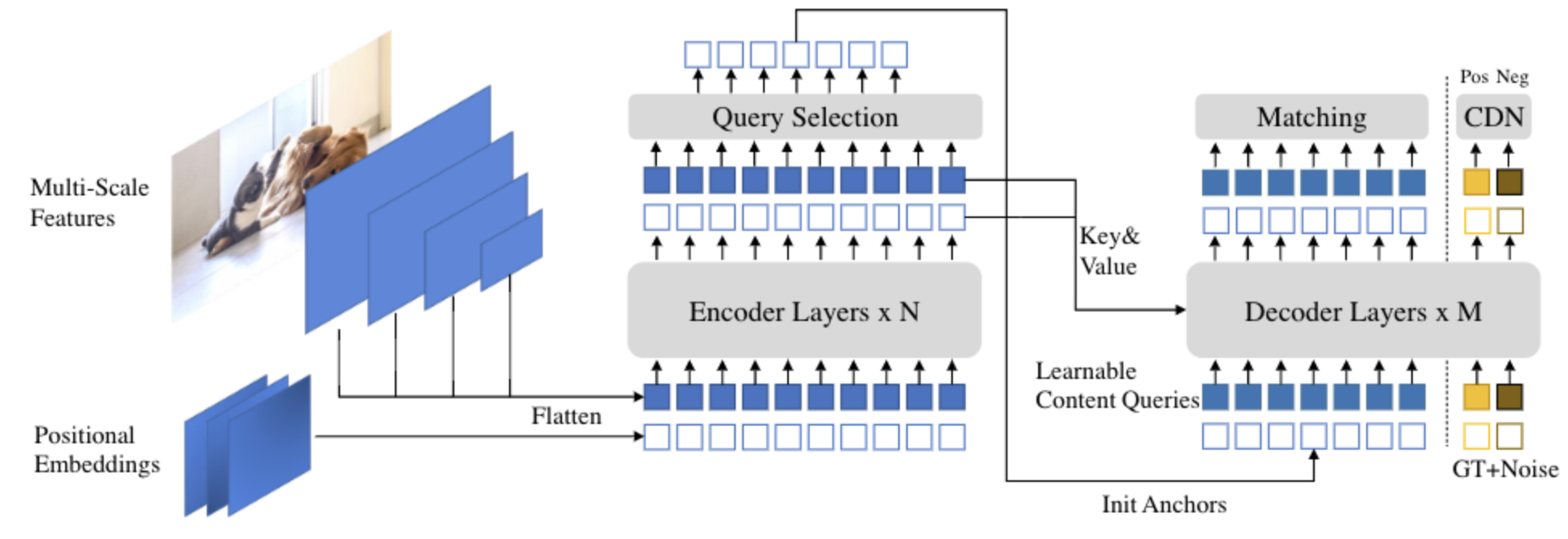
Uncertainty-minimal Query Selection(IoU soft label)
重要性
DAB-DETR对查询向量进行重构理解,将其解释为Anchor,DN-DETR通过查询降噪来应对匈牙利匹配的二义性所导致的训练时间长的问题,DINO提出从Encoder中选择Top-k特征进行学习等一系列方法,这都无疑向我们证明,查询向量很重要,选择好的Query能够让我们事半功倍。
加噪
匈牙利匹配不稳定导致坐标偏移量难以学习,进一步导致模型收敛速度慢。
DN-DETR中,对GT加噪后的数据作为decoder的输入,然后让decoder学习去噪,是的预测出来的结果逼近真实的GT。

加噪这部分会分出很多组出来,每一组采用的加噪是不一样的值,RT-DETR有正负两个样本。
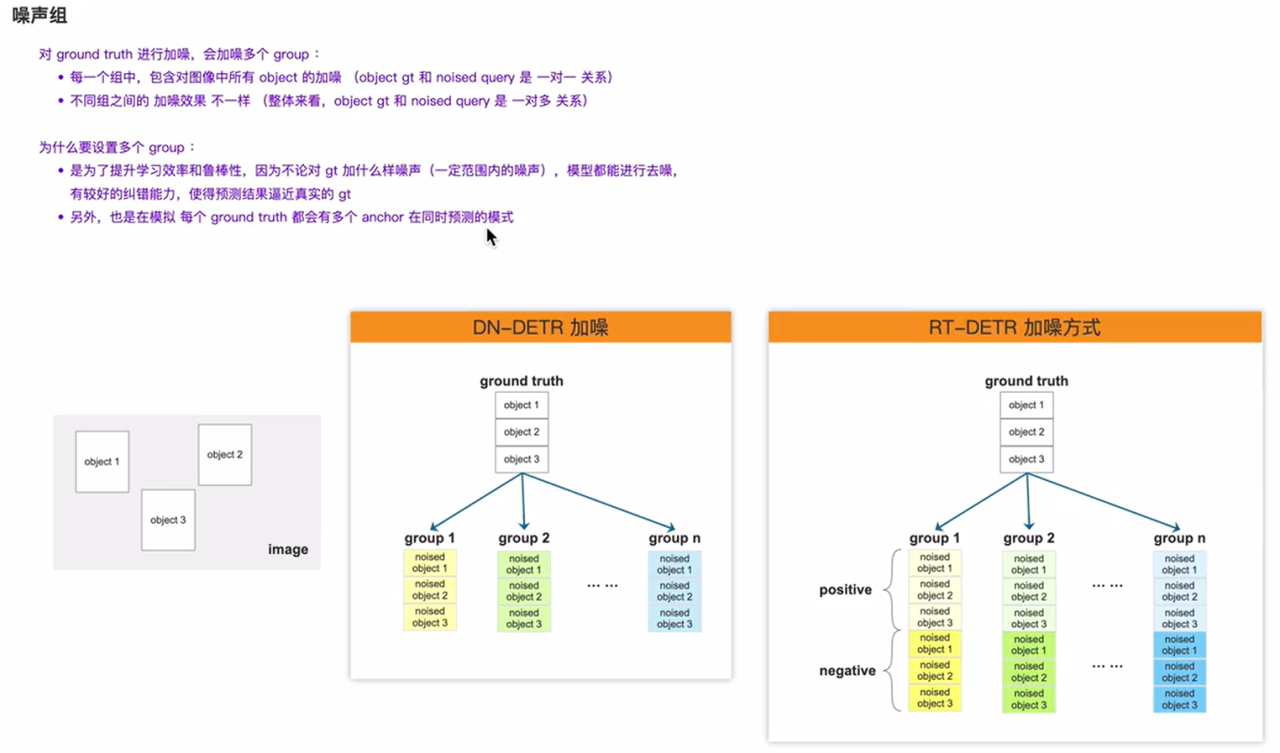
加噪操作主要是对原始的预测到的目标进行加噪,比如说预测两个类别分别以下
改进思路
由于分类分数和 IOU 分数的分布存在不一致,分类得分高的预测框并不一定是和 GT 最接近的框,这导致高分类分数低 IOU 的框会被选中,而低分类分数高 IOU 的框会被丢弃,这将会损害检测器的性能。
RT-DETR考虑通过在训练期间约束检测器对高 IOU 的特征产生高分类分数,对低 IOU 的特征产生低分类分数。故而,作者提出了 IoU-aware Query selection。从而使得模型根据分类分数选择的 Top-K 特征对应的预测框同时具有高分类分数和高 IOU 分数。
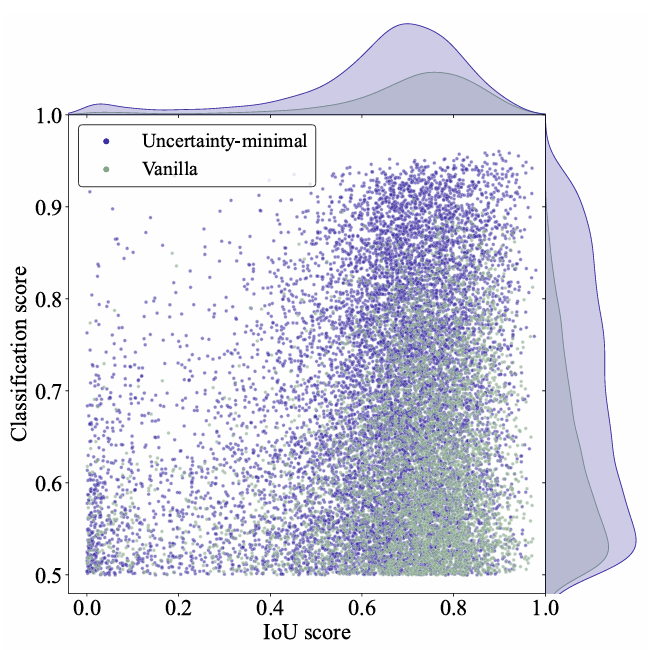
指的是预测的标签和类别,y是GT。
c是类别。
“IoU软标签”就是指将预测框与GT之间的IoU作为类别预测的标签。
Decoder
输入包括两部分(concatenate),一个是加噪后的GT,另外一个是通过IoU-aware选择出的topk的query用于选择做二分图匹配任务。如果是预测部分加噪GT的值都是None。
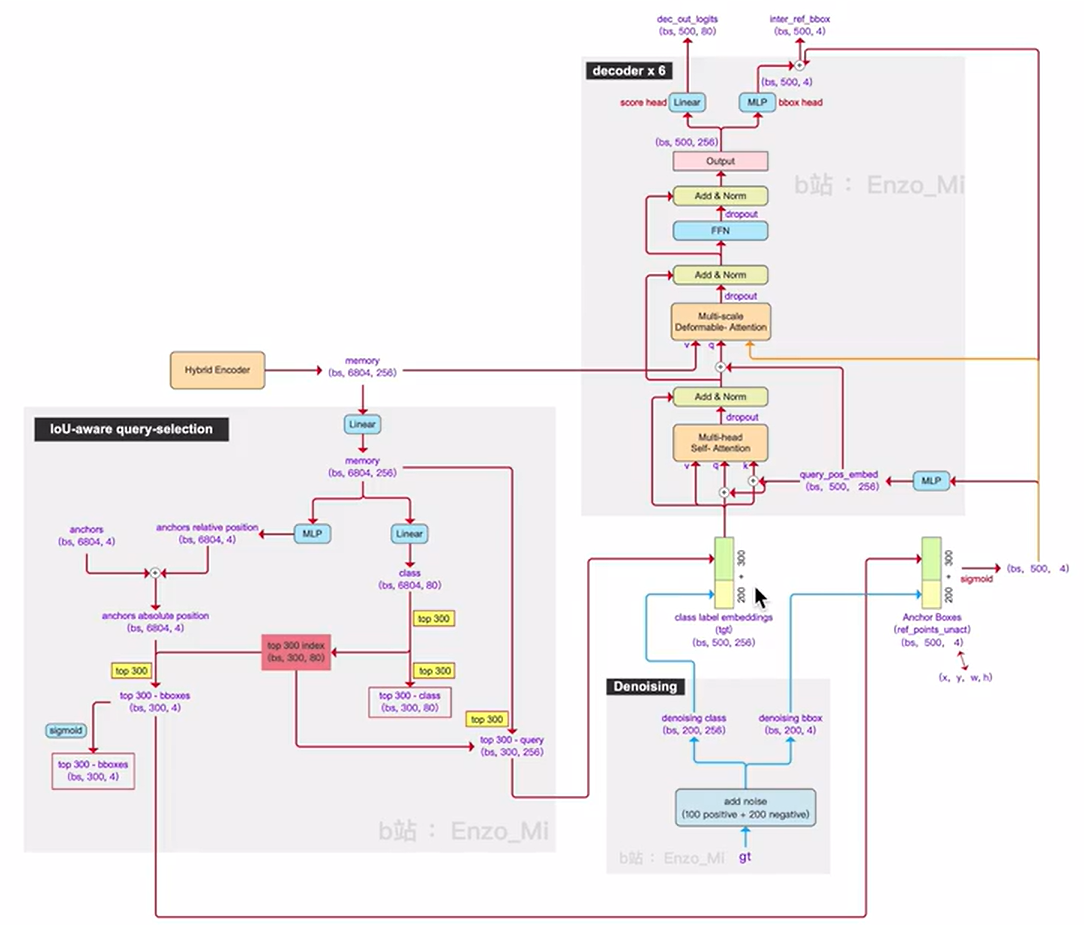
代码解读
https://blog.csdn.net/weixin_42479327/article/details/136037668
编码器code
# https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/hybrid_encoder.py
class HybridEncoder(nn.Layer):
__shared__ = ['depth_mult', 'act', 'trt', 'eval_size']
__inject__ = ['encoder_layer']
def __init__(self,
in_channels=[512, 1024, 2048],
feat_strides=[8, 16, 32],
hidden_dim=256,
use_encoder_idx=[2],
num_encoder_layers=1,
encoder_layer='TransformerLayer',
pe_temperature=10000,
expansion=1.0,
depth_mult=1.0,
act='silu',
trt=False,
eval_size=None):
super(HybridEncoder, self).__init__()
self.in_channels = in_channels
self.feat_strides = feat_strides
self.hidden_dim = hidden_dim
self.use_encoder_idx = use_encoder_idx
self.num_encoder_layers = num_encoder_layers
self.pe_temperature = pe_temperature
self.eval_size = eval_size
# channel projection
self.input_proj = nn.LayerList()
for in_channel in in_channels:
self.input_proj.append(
nn.Sequential(
nn.Conv2D(in_channel, hidden_dim, kernel_size=1, bias_attr=False),
nn.BatchNorm2D(
hidden_dim,
weight_attr=ParamAttr(regularizer=L2Decay(0.0)),
bias_attr=ParamAttr(regularizer=L2Decay(0.0)))))
# encoder transformer
self.encoder = nn.LayerList([
TransformerEncoder(encoder_layer, num_encoder_layers)
for _ in range(len(use_encoder_idx))
])
act = get_act_fn(
act, trt=trt) if act is None or isinstance(act, str, dict)) else act
# top-down fpn
self.lateral_convs = nn.LayerList()
self.fpn_blocks = nn.LayerList()
for idx in range(len(in_channels) - 1, 0, -1):
self.lateral_convs.append(
BaseConv(hidden_dim, hidden_dim, 1, 1, act=act))
self.fpn_blocks.append(
CSPRepLayer(
hidden_dim * 2,
hidden_dim,
round(3 * depth_mult),
act=act,
expansion=expansion))
# bottom-up pan
self.downsample_convs = nn.LayerList()
self.pan_blocks = nn.LayerList()
for idx in range(len(in_channels) - 1):
self.downsample_convs.append(
BaseConv(hidden_dim, hidden_dim, 3, stride=2, act=act))
self.pan_blocks.append(
CSPRepLayer(
hidden_dim * 2,
hidden_dim,
round(3 * depth_mult),
act=act,
expansion=expansion))
def forward(self, feats, for_mot=False):
assert len(feats) == len(self.in_channels)
# get projection features
proj_feats = [self.input_proj[i](feat) for i, feat in enumerate(feats)]
# encoder
if self.num_encoder_layers > 0:
for i, enc_ind in enumerate(self.use_encoder_idx):
h, w = proj_feats[enc_ind].shape[2:]
# flatten [B, C, H, W] to [B, HxW, C]
src_flatten = proj_feats[enc_ind].flatten(2).transpose(
[0, 2, 1])
if self.training or self.eval_size is None:
pos_embed = self.build_2d_sincos_position_embedding(
w, h, self.hidden_dim, self.pe_temperature)
else:
pos_embed = getattr(self, f'pos_embed{enc_ind}', None)
memory = self.encoder[i](src_flatten, pos_embed=pos_embed)
proj_feats[enc_ind] = memory.transpose([0, 2, 1]).reshape(
[-1, self.hidden_dim, h, w])
# top-down fpn
inner_outs = [proj_feats[-1]]
for idx in range(len(self.in_channels) - 1, 0, -1):
feat_heigh = inner_outs[0]
feat_low = proj_feats[idx - 1]
feat_heigh = self.lateral_convs[len(self.in_channels) - 1 - idx](
feat_heigh)
inner_outs[0] = feat_heigh
upsample_feat = F.interpolate(
feat_heigh, scale_factor=2., mode="nearest")
inner_out = self.fpn_blocks[len(self.in_channels) - 1 - idx](
paddle.concat(
[upsample_feat, feat_low], axis=1))
inner_outs.insert(0, inner_out)
# bottom-up pan
outs = [inner_outs[0]]
for idx in range(len(self.in_channels) - 1):
feat_low = outs[-1]
feat_height = inner_outs[idx + 1]
downsample_feat = self.downsample_convs[idx](feat_low)
out = self.pan_blocks[idx](paddle.concat(
[downsample_feat, feat_height], axis=1))
outs.append(out)
return outs
解码器code
解码器采用的是和DETR一样的结构
class RTDETRTransformer(nn.Layer):
__shared__ = ['num_classes', 'hidden_dim', 'eval_size']
def __init__(self,
num_classes=80,
hidden_dim=256,
num_queries=300,
position_embed_type='sine',
backbone_feat_channels=[512, 1024, 2048],
feat_strides=[8, 16, 32],
num_levels=3,
num_decoder_points=4,
nhead=8,
num_decoder_layers=6,
dim_feedforward=1024,
dropout=0.,
activation="relu",
num_denoising=100,
label_noise_ratio=0.5,
box_noise_scale=1.0,
learnt_init_query=True,
query_pos_head_inv_sig=False,
eval_size=None,
eval_idx=-1,
eps=1e-2):
super(RTDETRTransformer, self).__init__()
assert position_embed_type in ['sine', 'learned'], \
f'ValueError: position_embed_type not supported {position_embed_type}!'
assert len(backbone_feat_channels) <= num_levels
assert len(feat_strides) == len(backbone_feat_channels)
for _ in range(num_levels - len(feat_strides)):
feat_strides.append(feat_strides[-1] * 2)
self.hidden_dim = hidden_dim
self.nhead = nhead
self.feat_strides = feat_strides
self.num_levels = num_levels
self.num_classes = num_classes
self.num_queries = num_queries
self.eps = eps
self.num_decoder_layers = num_decoder_layers
self.eval_size = eval_size
# backbone feature projection
self._build_input_proj_layer(backbone_feat_channels)
# Transformer module
decoder_layer = TransformerDecoderLayer(
hidden_dim, nhead, dim_feedforward, dropout, activation, num_levels,
num_decoder_points)
self.decoder = TransformerDecoder(hidden_dim, decoder_layer,
num_decoder_layers, eval_idx)
# denoising part
self.denoising_class_embed = nn.Embedding(
num_classes,
hidden_dim,
weight_attr=ParamAttr(initializer=nn.initializer.Normal()))
self.num_denoising = num_denoising
self.label_noise_ratio = label_noise_ratio
self.box_noise_scale = box_noise_scale
# decoder embedding
self.learnt_init_query = learnt_init_query
if learnt_init_query:
self.tgt_embed = nn.Embedding(num_queries, hidden_dim)
self.query_pos_head = MLP(4, 2 * hidden_dim, hidden_dim, num_layers=2)
self.query_pos_head_inv_sig = query_pos_head_inv_sig
# encoder head
self.enc_output = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.LayerNorm(
hidden_dim,
weight_attr=ParamAttr(regularizer=L2Decay(0.0)),
bias_attr=ParamAttr(regularizer=L2Decay(0.0))))
self.enc_score_head = nn.Linear(hidden_dim, num_classes)
self.enc_bbox_head = MLP(hidden_dim, hidden_dim, 4, num_layers=3)
# decoder head
self.dec_score_head = nn.LayerList([
nn.Linear(hidden_dim, num_classes)
for _ in range(num_decoder_layers)
])
self.dec_bbox_head = nn.LayerList([
MLP(hidden_dim, hidden_dim, 4, num_layers=3)
for _ in range(num_decoder_layers)
])
self._reset_parameters()
def forward(self, feats, pad_mask=None, gt_meta=None, is_teacher=False):
# input projection and embedding
(memory, spatial_shapes,
level_start_index) = self._get_encoder_input(feats)
# prepare denoising training
if self.training:
denoising_class, denoising_bbox_unact, attn_mask, dn_meta = \
get_contrastive_denoising_training_group(gt_meta,
self.num_classes,
self.num_queries,
self.denoising_class_embed.weight,
self.num_denoising,
self.label_noise_ratio,
self.box_noise_scale)
else:
denoising_class, denoising_bbox_unact, attn_mask, dn_meta = None, None, None, None
target, init_ref_points_unact, enc_topk_bboxes, enc_topk_logits = \
self._get_decoder_input(
memory, spatial_shapes, denoising_class, denoising_bbox_unact,is_teacher)
# decoder
out_bboxes, out_logits = self.decoder(
target,
init_ref_points_unact,
memory,
spatial_shapes,
level_start_index,
self.dec_bbox_head,
self.dec_score_head,
self.query_pos_head,
attn_mask=attn_mask,
memory_mask=None,
query_pos_head_inv_sig=self.query_pos_head_inv_sig)
return (out_bboxes, out_logits, enc_topk_bboxes, enc_topk_logits,
dn_meta)
Q.E.D.