






Github: https://github.com/shaunyuan22/CFINet?tab=readme-ov-file
arXiv: https://arxiv.org/abs/2308.09534
# 难点 小目标检测具有的两个挑战:-
小目标检测的两个固有挑战:训练样本不足和质量低,以及兴趣区域预测的不确定性。
- 训练样本不足且质量低
- RoIs的不确定预测
贡献点
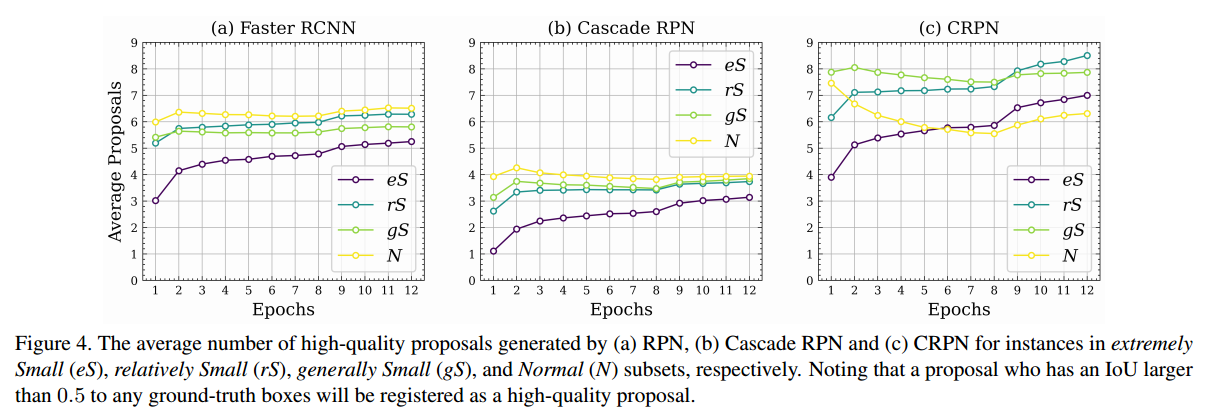
实验结果
SODA-D
驾驶场景,24828张高质量图像,278433个实例
9个类别:人、骑手、自行车、机动车辆、交通标志、交通信号灯、交通摄像头、警示灯。
SODA-A
2513航拍图像,872069 objects
9个类别:飞机、直升机、小型车辆、大型车辆、船舶、集装箱、储罐、游泳池、风车。
目标大小
SODA上的小目标分为:极小,相对小以及一般小。
消融实验
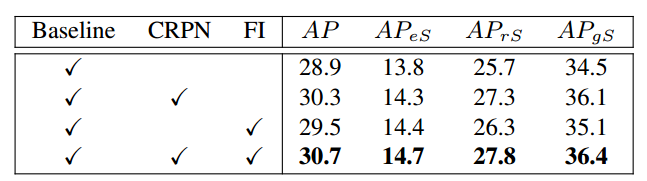
实验结果比较
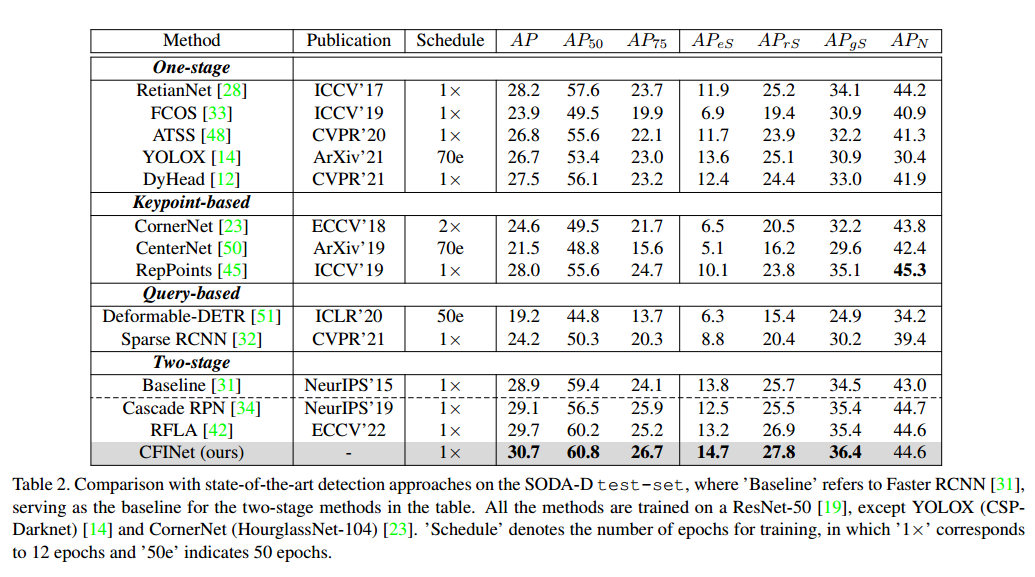
Method: CFINet

方法一:CRPN
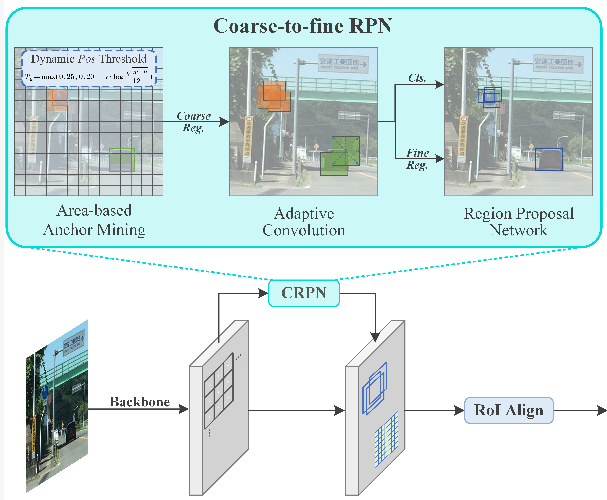
从Cascade RPN到Coarse-to-fine RPN
Cascade RPN的缺点:
- 固有属性的局限性,无法很好地处理极小的对象
- 级联RPN仅将单个金字塔层上符合条件的锚点标记为正锚点,而这种启发式方案直接丢弃了其他层次上仍然可以传递小物体存在和粗略位置信息的可能锚点。
Coarse-to-fine RPN:
- 基于区域(area)的锚点寻找策略,目的是使得不同大小的实例能有(相对)足够的潜在锚点。
- 假设物体w*h,任何一个锚点的IoU比T_a高就是“正”的。
公式:
其中一般取0.15,以及分母12代表的是SODA数据集中最小的面积,这两个参数(12:最小面积)主要是用于保持最优化以免被低质量先验淹没。
Loss Function
自定义的损失函数,该说不说目前很多顶级论文都有这部分自己设计一个损失函数再配合算法,是一个很大的加分项。
这个损失函数的公式如下:
-
注意事项
- 用交叉熵和IoU损失分别作为L_cls和L_reg
- \alpha_1 : \alpha_2=9 : 0.9
- c和f分别表示CRPN的粗糙阶段和精确阶段(coarse-stage and fine-stage)
方法二: FI
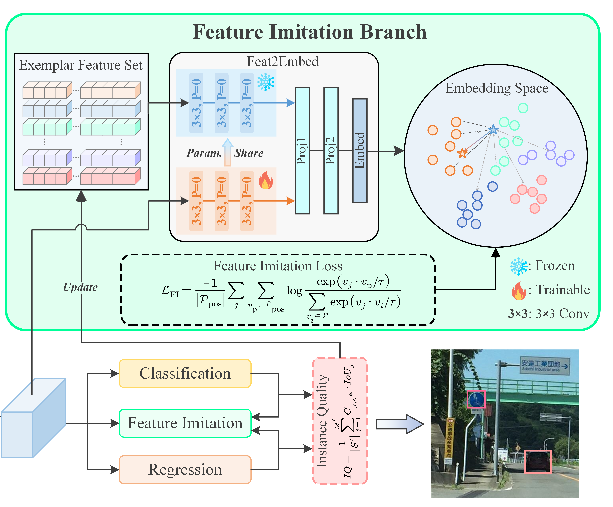
构建的原因
主要是对比于过去的方法(GAN进行超分辨率,相似学习,L2范数测量不同的RoI特性,这三者导致的区域特征高相似度失去了自己的特征以及空间同质化损害了模型的通用和鲁棒性)。
- 降低崩溃的原因。
- 避免内存负担。
- 实现端到端的优化。
模型的IQ
有这样子的一个假设,给定一个GT, math$g^*=(c^*,b^*)$ ,其中 math$c^*$ 和 math$g^*$ 分别表示的是标签label和边界框,那么假设模型输出 math$S=\{C_i,IoU_i\}_{i=1,2,...,M$ 其中 math$C_i\inR^{N+1}$N是类别数量,IoU是预测框与GT计算的值,然后我们就可以获得一个高质量的math$S^'$有math$S^'=\{(C_j,IoU_i)\}$,并且可以获得math$C_j$的索引,那么就可以定义IQ如下。
IQ可以作为当前模型检测能力的指标,使我们能够捕获具有精确定位和高置信度分类分数的高质量示例,而混淆模型的实例通常无法实现这两个目标。通过设置合适的阈值,我们可以选择合适的实例来构建教师特征集,并进行模仿过程。
Feat2Embed Module
进行3个3x3的卷积操作
Loss Function
FI head的目标:计算提案的RoI特征与嵌入空间中存储的高质量实例的RoI特征之间的相似性,从而将那些混淆模型的实例的特征拉近属于类别的示例特征,同时将其他类别和背景的特征分开。
为FI量身定制的损失函数如下:
P是样本集合,是pos和neg的∪,math $P=P_{pos}\cup P_{neg}$,$\tau$ 是温度,
FI算法分支训练

学习模型中的其他内容
RoI Align
RoIAlign 用于将任意尺寸感兴趣区域的特征图,都转换为具有固定尺寸 H×W 的小特征图。
RoIAlign 其实就是更精确版本的 RoIPooling,用双线性插值取代了。
RoIPooling中的直接取整的操作。具体可以看看这篇blog: https://blog.csdn.net/Bit_Coders/article/details/121203584目前观感最好的一篇。
来自论文Mask-RCNN。
模型代码
CRPN
# Copyright (c) OpenMMLab. All rights reserved.
from __future__ import division
import copy
import warnings
import torch
import torch.nn as nn
from mmcv import ConfigDict
from mmcv.ops import batched_nms
from mmcv.runner import ModuleList
from mmdet.core import (anchor_inside_flags, build_assigner, build_sampler,
images_to_levels, multi_apply, DynamicAssigner)
from mmdet.core.utils import select_single_mlvl
from ..builder import HEADS, build_head
from .base_dense_head import BaseDenseHead
from .dense_test_mixins import BBoxTestMixin
from .rpn_head import RPNHead
from .cascade_rpn_head import AdaptiveConv
@HEADS.register_module()
class StageRefineRPNHead(RPNHead):
"""Stage of CascadeRPNHead.
Args:
in_channels (int): Number of channels in the input feature map.
anchor_generator (dict): anchor generator config.
refine_cfg (dict): adaptation config.
refined_feature (bool, optional): whether update rpn feature.
Default: False.
with_cls (bool, optional): whether use classification branch.
Default: True.
sampling (bool, optional): whether use sampling. Default: True.
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None
"""
def __init__(self,
in_channels,
anchor_generator=dict(
type='AnchorGenerator',
scales=[2],
ratios=[1.0],
strides=[4, 8, 16, 32]),
refine_cfg=dict(
type='dilation',
dilation=3),
refine_reg_factor=50.0,
refined_feature=False,
anchor_lvl=False,
with_cls=True,
sampling=True,
init_cfg=None,
**kwargs):
assert refine_cfg['type'] in ['dilation', 'offset']
self.with_cls = with_cls
self.anchor_strides = anchor_generator['strides']
self.anchor_scales = anchor_generator['scales']
self.refined_feature = refined_feature
self.anchor_lvl = anchor_lvl
self.refine_cfg = refine_cfg
if self.refine_cfg['type'] == 'dilation':
self.refine_reg_factor = refine_reg_factor
super(StageRefineRPNHead, self).__init__(
in_channels,
anchor_generator=anchor_generator,
init_cfg=init_cfg,
**kwargs)
self.num_base_anchors = self.anchor_generator.num_base_anchors[0]
# override sampling and sampler
self.sampling = sampling
if self.train_cfg:
self.assigner = build_assigner(self.train_cfg.assigner)
# use PseudoSampler when sampling is False
if self.sampling and hasattr(self.train_cfg, 'sampler'):
sampler_cfg = self.train_cfg.sampler
else:
sampler_cfg = dict(type='PseudoSampler')
self.sampler = build_sampler(sampler_cfg, context=self)
if init_cfg is None:
self.init_cfg = dict(
type='Normal', std=0.01, override=[dict(name='rpn_reg')])
if self.with_cls:
self.init_cfg['override'].append(dict(name='rpn_cls'))
def _init_layers(self):
"""Init layers of a CascadeRPN stage."""
self.rpn_conv = AdaptiveConv(self.in_channels, self.feat_channels,
**self.refine_cfg)
if self.with_cls:
self.rpn_cls = nn.Conv2d(self.feat_channels,
self.num_anchors * self.cls_out_channels,
1)
self.rpn_reg = nn.Conv2d(self.feat_channels, self.num_anchors * 4, 1)
self.relu = nn.ReLU(inplace=True)
def forward_single(self, x, offset):
"""Forward function of single scale."""
refined_x = x
x = self.relu(self.rpn_conv(x, offset))
if self.refined_feature:
refined_x = x # update feature
cls_score = self.rpn_cls(x) if self.with_cls else None
bbox_pred = self.rpn_reg(x)
return refined_x, cls_score, bbox_pred
def forward(self, feats, offset_list=None):
"""Forward function."""
if offset_list is None:
offset_list = [None for _ in range(len(feats))]
return multi_apply(self.forward_single, feats, offset_list)
def write_csv(self, path, data):
import csv
with open(path, 'a+', newline='\n') as f:
csv_write = csv.writer(f)
csv_write.writerows(data)
def _anchor_targets_single(self,
flat_anchors,
valid_flags,
gt_bboxes,
gt_bboxes_ignore,
gt_labels,
img_meta,
num_base_anchors):
""" Get anchor targets for a single image. """
inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
img_meta['img_shape'][:2],
self.train_cfg.allowed_border)
if not inside_flags.any():
return (None,) * 7
# assign gt and sample anchors
flat_anchors = flat_anchors[inside_flags, :]
scale_factor = float(img_meta['scale_factor'][0])
assign_result, assigned_ign_inds = self.assigner.assign(
flat_anchors,
gt_bboxes,
gt_bboxes_ignore=gt_bboxes_ignore,
gt_labels=None,
num_base_anchors=num_base_anchors,
scale_ratio=scale_factor)
sampling_result = self.sampler.sample(assign_result, flat_anchors,
gt_bboxes)
num_anchors = flat_anchors.shape[0]
bbox_targets = torch.zeros_like(flat_anchors)
bbox_weights = torch.zeros_like(flat_anchors)
# labels and label_weights won't be used in the regression process of first stage
labels = flat_anchors.new_zeros(num_anchors, dtype=torch.long)
label_weights = flat_anchors.new_zeros(num_anchors, dtype=torch.float)
pos_inds = sampling_result.pos_inds
neg_inds = sampling_result.neg_inds
if len(pos_inds) > 0:
if not self.reg_decoded_bbox:
pos_bbox_targets = self.bbox_coder.encode(
sampling_result.pos_bboxes, sampling_result.pos_gt_bboxes)
else:
pos_bbox_targets = sampling_result.pos_gt_bboxes
bbox_targets[pos_inds, :] = pos_bbox_targets
bbox_weights[pos_inds, :] = 1.0
bbox_weights[assigned_ign_inds, :] = 0 # ignore original high-quality anchors
if gt_labels is None:
labels[pos_inds] = 1 # including ignore anchors
else:
labels[pos_inds] = gt_labels[
sampling_result.pos_assigned_gt_inds]
if self.train_cfg.pos_weight <= 0:
label_weights[pos_inds] = 1.0
label_weights[assigned_ign_inds] = 0
else:
label_weights[pos_inds] = self.train_cfg.pos_weight
label_weights[assigned_ign_inds] = 0
if len(neg_inds) > 0:
label_weights[neg_inds] = 1.0
label_weights[assigned_ign_inds] = 0
return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
neg_inds, assigned_ign_inds)
def anchor_targets(self,
anchor_list,
valid_flag_list,
gt_bboxes_list,
img_metas,
gt_bboxes_ignore_list=None,
gt_labels_list=None):
""" Compute targets for images in a batch """
num_imgs = len(img_metas)
assert len(anchor_list) == len(valid_flag_list) == num_imgs
# anchor number of multi levels
num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
# anchor number of each location
num_base_anchor_list = [self.num_base_anchors for i in range(num_imgs)]
concat_anchor_list = []
concat_valid_flag_list = []
for i in range(num_imgs):
assert len(anchor_list[i]) == len(valid_flag_list[i])
concat_anchor_list.append(torch.cat(anchor_list[i]))
concat_valid_flag_list.append(torch.cat(valid_flag_list[i]))
# compute targets for each image
if gt_bboxes_ignore_list is None:
gt_bboxes_ignore_list = [None for _ in range(num_imgs)]
if gt_labels_list is None:
gt_labels_list = [None for _ in range(num_imgs)]
(all_labels, all_label_weights, all_bbox_targets, all_bbox_weights,
pos_inds_list, neg_inds_list, assigned_ign_inds_list) = multi_apply(
self._anchor_targets_single,
concat_anchor_list,
concat_valid_flag_list,
gt_bboxes_list,
gt_bboxes_ignore_list,
gt_labels_list,
img_metas,
num_base_anchor_list)
# no valid anchors
if any([labels is None for labels in all_labels]):
return None
# sampled anchors of all images
num_total_pos = sum([max(inds.numel(), 1) for inds in pos_inds_list])
num_total_neg = sum([max(inds.numel(), 1) for inds in neg_inds_list])
# split targets to a list w.r.t. multiple levels
labels_list = images_to_levels(all_labels, num_level_anchors)
label_weights_list = images_to_levels(all_label_weights,
num_level_anchors)
bbox_targets_list = images_to_levels(all_bbox_targets,
num_level_anchors)
bbox_weights_list = images_to_levels(all_bbox_weights,
num_level_anchors)
ign_inds_list = images_to_levels(assigned_ign_inds_list,
num_level_anchors)
return (labels_list, label_weights_list, bbox_targets_list,
bbox_weights_list, num_total_pos, num_total_neg)
def get_targets(self,
anchor_list,
valid_flag_list,
gt_bboxes,
img_metas,
featmap_sizes,
gt_bboxes_ignore=None,
label_channels=1):
"""Compute regression and classification targets for anchors.
Args:
anchor_list (list[list]): Multi level anchors of each image.
valid_flag_list (list[list]): Multi level valid flags of each
image.
gt_bboxes (list[Tensor]): Ground truth bboxes of each image.
img_metas (list[dict]): Meta info of each image.
featmap_sizes (list[Tensor]): Feature mapsize each level
gt_bboxes_ignore (list[Tensor]): Ignore bboxes of each images
label_channels (int): Channel of label.
Returns:
cls_reg_targets (tuple)
"""
if isinstance(self.assigner, DynamicAssigner):
cls_reg_targets = self.anchor_targets(
anchor_list,
valid_flag_list,
gt_bboxes,
img_metas)
else:
cls_reg_targets = super(StageRefineRPNHead, self).get_targets(
anchor_list,
valid_flag_list,
gt_bboxes,
img_metas,
gt_bboxes_ignore_list=gt_bboxes_ignore,
label_channels=label_channels)
return cls_reg_targets
def anchor_offset(self, anchor_list, anchor_strides, featmap_sizes):
""" Get offset for deformable conv based on anchor shape
NOTE: currently support deformable kernel_size=3 and dilation=1
Args:
anchor_list (list[list[tensor])): [NI, NLVL, NA, 4] list of
multi-level anchors
anchor_strides (list[int]): anchor stride of each level
Returns:
offset_list (list[tensor]): [NLVL, NA, 2, 18]: offset of DeformConv
kernel.
"""
def _shape_offset(anchors, stride, ks=3, dilation=1):
# currently support kernel_size=3 and dilation=1
assert ks == 3 and dilation == 1
pad = (ks - 1) // 2
idx = torch.arange(-pad, pad + 1, dtype=dtype, device=device)
yy, xx = torch.meshgrid(idx, idx) # return order matters
xx = xx.reshape(-1)
yy = yy.reshape(-1)
w = (anchors[:, 2] - anchors[:, 0]) / stride
h = (anchors[:, 3] - anchors[:, 1]) / stride
w = w / (ks - 1) - dilation
h = h / (ks - 1) - dilation
offset_x = w[:, None] * xx # (NA, ks**2)
offset_y = h[:, None] * yy # (NA, ks**2)
return offset_x, offset_y
def _ctr_offset(anchors, stride, featmap_size):
feat_h, feat_w = featmap_size
assert len(anchors) == feat_h * feat_w
x = (anchors[:, 0] + anchors[:, 2]) * 0.5
y = (anchors[:, 1] + anchors[:, 3]) * 0.5
# compute centers on feature map
x = x / stride
y = y / stride
# compute predefine centers
xx = torch.arange(0, feat_w, device=anchors.device)
yy = torch.arange(0, feat_h, device=anchors.device)
yy, xx = torch.meshgrid(yy, xx)
xx = xx.reshape(-1).type_as(x)
yy = yy.reshape(-1).type_as(y)
offset_x = x - xx # (NA, )
offset_y = y - yy # (NA, )
return offset_x, offset_y
num_imgs = len(anchor_list)
num_lvls = len(anchor_list[0])
dtype = anchor_list[0][0].dtype
device = anchor_list[0][0].device
num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
offset_list = []
for i in range(num_imgs):
mlvl_offset = []
for lvl in range(num_lvls):
c_offset_x, c_offset_y = _ctr_offset(anchor_list[i][lvl],
anchor_strides[lvl],
featmap_sizes[lvl])
s_offset_x, s_offset_y = _shape_offset(anchor_list[i][lvl],
anchor_strides[lvl])
# offset = ctr_offset + shape_offset
offset_x = s_offset_x + c_offset_x[:, None]
offset_y = s_offset_y + c_offset_y[:, None]
# offset order (y0, x0, y1, x2, .., y8, x8, y9, x9)
offset = torch.stack([offset_y, offset_x], dim=-1)
offset = offset.reshape(offset.size(0), -1) # [NA, 2*ks**2]
mlvl_offset.append(offset)
offset_list.append(torch.cat(mlvl_offset)) # [totalNA, 2*ks**2]
offset_list = images_to_levels(offset_list, num_level_anchors)
return offset_list
def loss_single(self, cls_score, bbox_pred, anchors, labels, label_weights,
bbox_targets, bbox_weights, num_total_samples):
"""Loss function on single scale."""
# classification loss
if self.with_cls:
labels = labels.reshape(-1)
label_weights = label_weights.reshape(-1)
cls_score = cls_score.permute(0, 2, 3,
1).reshape(-1, self.cls_out_channels)
loss_cls = self.loss_cls(
cls_score, labels, label_weights, avg_factor=num_total_samples)
# regression loss
bbox_targets = bbox_targets.reshape(-1, 4)
bbox_weights = bbox_weights.reshape(-1, 4)
bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
if self.reg_decoded_bbox:
# When the regression loss (e.g. `IouLoss`, `GIouLoss`)
# is applied directly on the decoded bounding boxes, it
# decodes the already encoded coordinates to absolute format.
anchors = anchors.reshape(-1, 4)
bbox_pred = self.bbox_coder.decode(anchors, bbox_pred)
loss_reg = self.loss_bbox(
bbox_pred,
bbox_targets,
bbox_weights,
avg_factor=num_total_samples)
if self.with_cls:
return loss_cls, loss_reg
return None, loss_reg
def loss(self,
anchor_list,
valid_flag_list,
cls_scores,
bbox_preds,
gt_bboxes,
img_metas,
gt_bboxes_ignore=None):
"""Compute losses of the head.
Args:
anchor_list (list[list]): Multi level anchors of each image.
cls_scores (list[Tensor]): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W)
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W)
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss. Default: None
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
featmap_sizes = [featmap.size()[-2:] for featmap in bbox_preds]
label_channels = self.cls_out_channels if self.use_sigmoid_cls else 1
cls_reg_targets = self.get_targets(
anchor_list,
valid_flag_list,
gt_bboxes,
img_metas,
featmap_sizes,
gt_bboxes_ignore=gt_bboxes_ignore,
label_channels=label_channels)
if cls_reg_targets is None:
return None
(labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
num_total_pos, num_total_neg) = cls_reg_targets
# with open('res-rrpn-12.txt', 'a+') as f:
# content = img_metas[0]['ori_filename'] + " " + str(num_total_pos) + "\n"
# f.writelines(content)
# f.close()
if self.sampling:
num_total_samples = num_total_pos + num_total_neg
else:
# 200 is hard-coded average factor, which follows guided anchoring.
num_total_samples = sum([label.numel()
for label in labels_list]) / self.refine_reg_factor
# change per image, per level anchor_list to per_level, per_image
mlvl_anchor_list = list(zip(*anchor_list))
# concat mlvl_anchor_list
mlvl_anchor_list = [
torch.cat(anchors, dim=0) for anchors in mlvl_anchor_list
]
losses = multi_apply(
self.loss_single,
cls_scores,
bbox_preds,
mlvl_anchor_list,
labels_list,
label_weights_list,
bbox_targets_list,
bbox_weights_list,
num_total_samples=num_total_samples)
if self.with_cls:
return dict(loss_rpn_cls=losses[0], loss_rpn_reg=losses[1])
return dict(loss_rpn_reg=losses[1])
def get_bboxes(self,
anchor_list,
cls_scores,
bbox_preds,
img_metas,
cfg,
rescale=False):
"""Get proposal predict.
Args:
anchor_list (list[list]): Multi level anchors of each image.
cls_scores (list[Tensor]): Classification scores for all
scale levels, each is a 4D-tensor, has shape
(batch_size, num_priors * num_classes, H, W).
bbox_preds (list[Tensor]): Box energies / deltas for all
scale levels, each is a 4D-tensor, has shape
(batch_size, num_priors * 4, H, W).
img_metas (list[dict], Optional): Image meta info. Default None.
cfg (mmcv.Config, Optional): Test / postprocessing configuration,
if None, test_cfg would be used.
rescale (bool): If True, return boxes in original image space.
Default: False.
Returns:
Tensor: Labeled boxes in shape (n, 5), where the first 4 columns
are bounding box positions (tl_x, tl_y, br_x, br_y) and the
5-th column is a score between 0 and 1.
"""
assert len(cls_scores) == len(bbox_preds)
result_list = []
for img_id in range(len(img_metas)):
cls_score_list = select_single_mlvl(cls_scores, img_id)
bbox_pred_list = select_single_mlvl(bbox_preds, img_id)
img_shape = img_metas[img_id]['img_shape']
scale_factor = img_metas[img_id]['scale_factor']
proposals = self._get_bboxes_single(
cls_score_list, bbox_pred_list, anchor_list[img_id],
img_shape, scale_factor, cfg, rescale)
result_list.append(proposals)
return result_list
def _get_bboxes_single(self,
cls_scores,
bbox_preds,
mlvl_anchors,
img_shape,
scale_factor,
cfg,
rescale=False):
"""Transform outputs of a single image into bbox predictions.
Args:
cls_scores (list[Tensor]): Box scores from all scale
levels of a single image, each item has shape
(num_anchors * num_classes, H, W).
bbox_preds (list[Tensor]): Box energies / deltas from
all scale levels of a single image, each item has
shape (num_anchors * 4, H, W).
mlvl_anchors (list[Tensor]): Box reference from all scale
levels of a single image, each item has shape
(num_total_anchors, 4).
img_shape (tuple[int]): Shape of the input image,
(height, width, 3).
scale_factor (ndarray): Scale factor of the image arange as
(w_scale, h_scale, w_scale, h_scale).
cfg (mmcv.Config): Test / postprocessing configuration,
if None, test_cfg would be used.
rescale (bool): If True, return boxes in original image space.
Default False.
Returns:
Tensor: Labeled boxes in shape (n, 5), where the first 4 columns
are bounding box positions (tl_x, tl_y, br_x, br_y) and the
5-th column is a score between 0 and 1.
"""
cfg = self.test_cfg if cfg is None else cfg
cfg = copy.deepcopy(cfg)
# bboxes from different level should be independent during NMS,
# level_ids are used as labels for batched NMS to separate them
level_ids = []
mlvl_scores = []
mlvl_bbox_preds = []
mlvl_valid_anchors = []
nms_pre = cfg.get('nms_pre', -1)
for idx in range(len(cls_scores)):
rpn_cls_score = cls_scores[idx]
rpn_bbox_pred = bbox_preds[idx]
assert rpn_cls_score.size()[-2:] == rpn_bbox_pred.size()[-2:]
rpn_cls_score = rpn_cls_score.permute(1, 2, 0)
if self.use_sigmoid_cls:
rpn_cls_score = rpn_cls_score.reshape(-1)
scores = rpn_cls_score.sigmoid()
else:
rpn_cls_score = rpn_cls_score.reshape(-1, 2)
# We set FG labels to [0, num_class-1] and BG label to
# num_class in RPN head since mmdet v2.5, which is unified to
# be consistent with other head since mmdet v2.0. In mmdet v2.0
# to v2.4 we keep BG label as 0 and FG label as 1 in rpn head.
scores = rpn_cls_score.softmax(dim=1)[:, 0]
rpn_bbox_pred = rpn_bbox_pred.permute(1, 2, 0).reshape(-1, 4)
anchors = mlvl_anchors[idx]
if 0 < nms_pre < scores.shape[0]:
# sort is faster than topk
# _, topk_inds = scores.topk(cfg.nms_pre)
ranked_scores, rank_inds = scores.sort(descending=True)
topk_inds = rank_inds[:nms_pre]
scores = ranked_scores[:nms_pre]
rpn_bbox_pred = rpn_bbox_pred[topk_inds, :]
anchors = anchors[topk_inds, :]
mlvl_scores.append(scores)
mlvl_bbox_preds.append(rpn_bbox_pred)
mlvl_valid_anchors.append(anchors)
level_ids.append(
scores.new_full((scores.size(0),), idx, dtype=torch.long))
scores = torch.cat(mlvl_scores)
anchors = torch.cat(mlvl_valid_anchors)
rpn_bbox_pred = torch.cat(mlvl_bbox_preds)
proposals = self.bbox_coder.decode(
anchors, rpn_bbox_pred, max_shape=img_shape)
ids = torch.cat(level_ids)
if cfg.min_bbox_size >= 0:
w = proposals[:, 2] - proposals[:, 0]
h = proposals[:, 3] - proposals[:, 1]
valid_mask = (w > cfg.min_bbox_size) & (h > cfg.min_bbox_size)
if not valid_mask.all():
proposals = proposals[valid_mask]
if proposals.numel() == 0:
print()
scores = scores[valid_mask]
ids = ids[valid_mask]
# deprecate arguments warning
if 'nms' not in cfg or 'max_num' in cfg or 'nms_thr' in cfg:
warnings.warn(
'In rpn_proposal or test_cfg, '
'nms_thr has been moved to a dict named nms as '
'iou_threshold, max_num has been renamed as max_per_img, '
'name of original arguments and the way to specify '
'iou_threshold of NMS will be deprecated.')
if 'nms' not in cfg:
cfg.nms = ConfigDict(dict(type='nms', iou_threshold=cfg.nms_thr))
if 'max_num' in cfg:
if 'max_per_img' in cfg:
assert cfg.max_num == cfg.max_per_img, f'You ' \
f'set max_num and ' \
f'max_per_img at the same time, but get {cfg.max_num} ' \
f'and {cfg.max_per_img} respectively' \
'Please delete max_num which will be deprecated.'
else:
cfg.max_per_img = cfg.max_num
if 'nms_thr' in cfg:
assert cfg.nms.iou_threshold == cfg.nms_thr, f'You set' \
f' iou_threshold in nms and ' \
f'nms_thr at the same time, but get' \
f' {cfg.nms.iou_threshold} and {cfg.nms_thr}' \
f' respectively. Please delete the nms_thr ' \
f'which will be deprecated.'
if proposals.numel() > 0:
dets, _ = batched_nms(proposals, scores, ids, cfg.nms)
else:
return proposals.new_zeros(0, 5)
return dets[:cfg.max_per_img]
def refine_bboxes(self, anchor_list, bbox_preds, img_metas):
"""Refine bboxes through stages."""
num_levels = len(bbox_preds)
new_anchor_list = []
for img_id in range(len(img_metas)):
mlvl_anchors = []
for i in range(num_levels):
bbox_pred = bbox_preds[i][img_id].detach()
bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, 4)
img_shape = img_metas[img_id]['img_shape']
bboxes = self.bbox_coder.decode(anchor_list[img_id][i],
bbox_pred, img_shape)
mlvl_anchors.append(bboxes)
new_anchor_list.append(mlvl_anchors)
return new_anchor_list
def get_anchors_gflops(self, featmap_sizes, device='cuda'):
"""
dummy forward for calculating GFLOPS in rrpn
"""
num_imgs = len(featmap_sizes)
# since feature map sizes of all images are the same, we only compute
# anchors for one time
multi_level_anchors = self.prior_generator.grid_priors(
featmap_sizes, device=device)
anchor_list = [multi_level_anchors for _ in range(num_imgs)]
return anchor_list
def refine_bboxes_gflops(self, anchor_list, bbox_preds):
"""
dummy forward for calculating GFLOPS in rrpn
"""
num_imgs = 1
num_levels = len(bbox_preds)
new_anchor_list = []
for img_id in range(num_imgs):
mlvl_anchors = []
for i in range(num_levels):
bbox_pred = bbox_preds[i][img_id].detach()
bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, 4)
img_shape = (1200, 1200, 3)
bboxes = self.bbox_coder.decode(anchor_list[img_id][i],
bbox_pred, img_shape)
mlvl_anchors.append(bboxes)
new_anchor_list.append(mlvl_anchors)
return new_anchor_list
@HEADS.register_module()
class CRPNHead(BaseDenseHead, BBoxTestMixin):
def __init__(self, num_stages, stages, train_cfg, test_cfg, init_cfg=None):
super(CRPNHead, self).__init__(init_cfg)
assert num_stages == len(stages)
self.num_stages = num_stages
# Be careful! Pretrained weights cannot be loaded when use
# nn.ModuleList
self.stages = ModuleList()
for i in range(len(stages)):
train_cfg_i = train_cfg[i] if train_cfg is not None else None
stages[i].update(train_cfg=train_cfg_i)
stages[i].update(test_cfg=test_cfg)
self.stages.append(build_head(stages[i]))
self.train_cfg = train_cfg
self.test_cfg = test_cfg
def forward(self, x):
featmap_sizes = [featmap.size()[-2:] for featmap in x]
device = x[0].device
anchor_list = self.stages[0].get_anchors_gflops(featmap_sizes, device=device)
for i in range(self.num_stages):
stage = self.stages[i]
if stage.refine_cfg['type'] == 'offset':
offset_list = stage.anchor_offset(anchor_list,
stage.anchor_strides,
featmap_sizes)
else:
offset_list = None
x, cls_score, bbox_pred = stage(x, offset_list)
if i < self.num_stages - 1:
anchor_list = stage.refine_bboxes_gflops(anchor_list, bbox_pred)
print()
return cls_score, bbox_pred
def forward_train(self,
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None):
"""Forward train function."""
assert gt_labels is None, 'RPN does not require gt_labels'
featmap_sizes = [featmap.size()[-2:] for featmap in x]
device = x[0].device
anchor_list, valid_flag_list = self.stages[0].get_anchors(
featmap_sizes, img_metas, device=device)
losses = dict()
for i in range(self.num_stages):
stage = self.stages[i]
if stage.refine_cfg['type'] == 'offset':
offset_list = stage.anchor_offset(anchor_list,
stage.anchor_strides,
featmap_sizes)
else:
offset_list = None
x, cls_score, bbox_pred = stage(x, offset_list)
rpn_loss_inputs = (anchor_list, valid_flag_list, cls_score,
bbox_pred, gt_bboxes, img_metas)
stage_loss = stage.loss(*rpn_loss_inputs)
for name, value in stage_loss.items():
losses['s{}.{}'.format(i, name)] = value
# refine boxes
if i < self.num_stages - 1:
anchor_list = stage.refine_bboxes(anchor_list, bbox_pred,
img_metas)
if proposal_cfg is None:
return losses
else:
proposal_list = self.stages[-1].get_bboxes(anchor_list, cls_score,
bbox_pred, img_metas,
proposal_cfg)
return losses, proposal_list
def loss(self):
"""loss() is implemented in StageCascadeRPNHead."""
pass
def get_bboxes(self):
"""get_bboxes() is implemented in StageCascadeRPNHead."""
pass
def simple_test_rpn(self, x, img_metas):
"""Simple forward test function."""
featmap_sizes = [featmap.size()[-2:] for featmap in x]
device = x[0].device
anchor_list, _ = self.stages[0].get_anchors(
featmap_sizes, img_metas, device=device)
for i in range(self.num_stages):
stage = self.stages[i]
if stage.refine_cfg['type'] == 'offset':
offset_list = stage.anchor_offset(anchor_list,
stage.anchor_strides,
featmap_sizes)
else:
offset_list = None
x, cls_score, bbox_pred = stage(x, offset_list)
if i < self.num_stages - 1:
anchor_list = stage.refine_bboxes(anchor_list, bbox_pred,
img_metas)
proposal_list = self.stages[-1].get_bboxes(anchor_list, cls_score,
bbox_pred, img_metas,
self.test_cfg)
return proposal_list
FI
# Copyright (c) OpenMMLab. All rights reserved.
import torch
import numpy as np
from mmdet.core import bbox2result, bbox2roi, build_assigner, build_sampler
from ..builder import HEADS, build_head, build_roi_extractor
from .base_roi_head import BaseRoIHead
from .test_mixins import BBoxTestMixin, MaskTestMixin
import os
import cv2
import time
import torch.nn as nn
import torch.nn.functional as F
import shutil
from mmcv.cnn import ConvModule
@HEADS.register_module()
class FIRoIHead(BaseRoIHead, BBoxTestMixin, MaskTestMixin):
"""Simplest base roi head including one bbox head and one mask head."""
def __init__(self,
roi_size=7,
num_gpus=1,
num_con_queue=256,
num_save_feats=300,
enc_output_dim=512,
proj_output_dim=128,
temperature=0.07,
ins_quality_assess_cfg=dict(
cls_score=0.00,
hq_score=0.01,
lq_score=0.005,
hq_pro_counts_thr=2),
con_sampler_cfg=dict(
num=128,
pos_fraction=[0.5, 0.25, 0.125]),
con_queue_dir=None,
num_classes=9,
iq_loss_weights=[0.5, 0.1, 0.05],
contrast_loss_weights=0.5,
hq_gt_aug_cfg=dict(
trans_range=[0.3, 0.5],
trans_num=2,
rescale_range=[0.97, 1.03],
rescale_num=2),
aug_roi_extractor=None,
init_cfg=dict(type='Normal', std=0.01,
override=[dict(name='fc_enc'), dict(name='fc_proj')]),
norm_cfg=dict(type='GN', num_groups=32, requires_grad=True),
*args,
**kwargs):
super(FIRoIHead, self).__init__(
*args, init_cfg=init_cfg, **kwargs)
self.roi_size = roi_size
self.num_gpus = num_gpus
self.num_con_queue = num_con_queue
self.num_save_feats = num_save_feats
assert self.num_con_queue >= con_sampler_cfg['num']
self.con_sampler_cfg = con_sampler_cfg
self.con_sample_num = self.con_sampler_cfg['num']
self.temperature = temperature
self.iq_cls_score = ins_quality_assess_cfg['cls_score']
self.hq_score = ins_quality_assess_cfg['hq_score']
self.lq_score = ins_quality_assess_cfg['lq_score']
self.hq_pro_counts_thr = ins_quality_assess_cfg['hq_pro_counts_thr']
self.hq_gt_aug_cfg = hq_gt_aug_cfg
if self.training:
self._mkdir(con_queue_dir, num_gpus)
self.con_queue_dir = con_queue_dir
self.num_classes = num_classes
if aug_roi_extractor is None:
aug_roi_extractor = dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32])
self.aug_roi_extractor = build_roi_extractor(aug_roi_extractor)
enc_input_dim = self.bbox_roi_extractor.out_channels # roi_size ** 2 * self.bbox_roi_extractor.out_channels
self.fc_enc = self._init_fc_enc(enc_input_dim, enc_output_dim)
self.fc_proj = nn.Linear(enc_output_dim, proj_output_dim)
self.relu = nn.ReLU(inplace=False)
self.iq_loss_weights = iq_loss_weights
self.contrast_loss_weights = contrast_loss_weights
self.comp_convs = self._add_comp_convs(self.bbox_roi_extractor.out_channels,
roi_size, norm_cfg, act_cfg=None)
def _add_comp_convs(self, in_channels, roi_feat_size, norm_cfg, act_cfg):
comp_convs = nn.ModuleList()
for i in range(roi_feat_size//2):
comp_convs.append(
ConvModule(in_channels, in_channels, 3, norm_cfg=norm_cfg, act_cfg=act_cfg)
)
return comp_convs
def _init_fc_enc(self, enc_input_dim, enc_output_dim):
fc_enc = nn.ModuleList()
fc_enc.append(nn.Linear(enc_input_dim, enc_output_dim))
fc_enc.append(nn.Linear(enc_output_dim, enc_output_dim))
return fc_enc
def _mkdir(self, con_queue_dir, num_gpus):
if os.path.exists(con_queue_dir):
shutil.rmtree(con_queue_dir)
os.mkdir(con_queue_dir)
for i in range(num_gpus):
os.makedirs(os.path.join(con_queue_dir, str(i)))
def init_assigner_sampler(self):
"""Initialize assigner and sampler."""
self.bbox_assigner = None
self.bbox_sampler = None
if self.train_cfg:
self.bbox_assigner = build_assigner(
self.train_cfg.assigner)
self.bbox_sampler = build_sampler(
self.train_cfg.sampler, context=self)
def init_bbox_head(self, bbox_roi_extractor, bbox_head):
"""Initialize ``bbox_head``"""
self.bbox_roi_extractor = build_roi_extractor(bbox_roi_extractor)
self.bbox_head = build_head(bbox_head)
def init_mask_head(self, mask_roi_extractor, mask_head):
"""Initialize ``mask_head``"""
if mask_roi_extractor is not None:
self.mask_roi_extractor = build_roi_extractor(mask_roi_extractor)
self.share_roi_extractor = False
else:
self.share_roi_extractor = True
self.mask_roi_extractor = self.bbox_roi_extractor
self.mask_head = build_head(mask_head)
def forward_dummy(self, x, proposals):
"""Dummy forward function."""
# bbox head
outs = ()
rois = bbox2roi([proposals])
if self.with_bbox:
bbox_results = self._bbox_forward(x, rois)
outs = outs + (bbox_results['cls_score'],
bbox_results['bbox_pred'])
# mask head
if self.with_mask:
mask_rois = rois[:100]
mask_results = self._mask_forward(x, mask_rois)
outs = outs + (mask_results['mask_pred'], )
return outs
def forward_train(self,
x,
img_metas,
proposal_list,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None,
gt_masks=None,
**kwargs):
"""
Args:
x (list[Tensor]): list of multi-level img features.
img_metas (list[dict]): list of image info dict where each dict
has: 'img_shape', 'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
For details on the values of these keys see
`mmdet/datasets/pipelines/formatting.py:Collect`.
proposals (list[Tensors]): list of region proposals.
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels (list[Tensor]): class indices corresponding to each box
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss.
gt_masks (None | Tensor) : true segmentation masks for each box
used if the architecture supports a segmentation task.
Returns:
dict[str, Tensor]: a dictionary of loss components
"""
# assign gts and sample proposals
if self.with_bbox or self.with_mask:
num_imgs = len(img_metas)
if gt_bboxes_ignore is None:
gt_bboxes_ignore = [None for _ in range(num_imgs)]
assign_results = []
sampling_results = []
for i in range(num_imgs):
assign_result = self.bbox_assigner.assign(
proposal_list[i], gt_bboxes[i], gt_bboxes_ignore[i],
gt_labels[i])
sampling_result = self.bbox_sampler.sample(
assign_result,
proposal_list[i],
gt_bboxes[i],
gt_labels[i],
feats=[lvl_feat[i][None] for lvl_feat in x])
assign_results.append(assign_result)
sampling_results.append(sampling_result)
losses = dict()
# bbox head forward and loss
if self.with_bbox:
bbox_results = self._bbox_forward_train(
x, assign_results, sampling_results,
gt_bboxes, gt_labels, img_metas)
# conf = F.softmax(scores, dim=1)
losses.update(bbox_results['loss_bbox'])
# mask head forward and loss
if self.with_mask:
mask_results = self._mask_forward_train(x, sampling_results,
bbox_results['bbox_feats'],
gt_masks, img_metas)
losses.update(mask_results['loss_mask'])
return losses
def _bbox_forward(self, x, rois):
"""Box head forward function used in both training and testing."""
# TODO: a more flexible way to decide which feature maps to use
bbox_feats = self.bbox_roi_extractor(
x[:self.bbox_roi_extractor.num_inputs], rois)
if self.with_shared_head:
bbox_feats = self.shared_head(bbox_feats)
feat_weights = bbox_feats.clone()
for conv in self.comp_convs:
feat_weights = conv(feat_weights)
comp_feats = feat_weights.clone()
feat_weights = F.softmax(feat_weights, dim=1)
_, c, h, w = bbox_feats.size()
weights = feat_weights.view(_, c, 1, 1).repeat(1, 1, h, w) + 1
bbox_feats = bbox_feats * weights
cls_score, bbox_pred = self.bbox_head(bbox_feats)
bbox_results = dict(
cls_score=cls_score, bbox_pred=bbox_pred, bbox_feats=bbox_feats, comp_feats=comp_feats)
return bbox_results
def get_area(self, gt_bboxes):
areas = (gt_bboxes[:, 2] - gt_bboxes[:, 0]) * \
(gt_bboxes[:, 3] - gt_bboxes[:, 1]) / 2.25
return areas.tolist()
def write_csv(self, path, data):
import csv
with open(path, 'a+', newline='\n') as f:
csv_write = csv.writer(f)
csv_write.writerows(data)
def _ins_quality_assess(self, cls_score, assign_result, sampling_result,
eps=1e-6):
""" Compute the quality of instances in a single image
The quality of an instance is defined:
iq = 1 / N * (IoU * Score)_i (i: {1, 2, ..., N})
"""
with torch.no_grad():
num_gts = sampling_result.num_gts
assign_pos_inds = sampling_result.pos_inds
num_pos = len(assign_pos_inds)
pos_gt_labels = sampling_result.pos_gt_labels
scores = F.softmax(cls_score[:num_pos, :], dim=-1)
scores = torch.gather(
scores, dim=1, index=pos_gt_labels.view(-1, 1)).view(-1) # (num_pos, )
iq_candi_inds = scores >= self.iq_cls_score
if torch.sum(iq_candi_inds) == 0:
return scores.new_zeros(num_gts), scores.new_zeros(num_gts)
else:
scores = scores[iq_candi_inds]
num_pos = len(scores)
pos_ious = assign_result.max_overlaps[assign_pos_inds[iq_candi_inds]] # (num_pos, )
pos_is_pro = (sampling_result.pos_is_gt == 0)[iq_candi_inds] # (num_pos, )
pos_assigned_gt_inds = sampling_result.pos_assigned_gt_inds[iq_candi_inds] # (num_pos, )
gt_ind_mask = torch.cat([pos_assigned_gt_inds == i for i in range(num_gts)]
).contiguous().view(num_gts, num_pos)
# compute proposals (ious and scores) only
# TODO: enusre the return length is num_gts
iq = pos_ious * pos_is_pro * gt_ind_mask * scores # (num_gts, num_pos)
iq_sum = torch.sum(iq, dim=1) # (num_gts, )
iq_count = torch.sum(gt_ind_mask * pos_is_pro, dim=1) # (num_gts, )
iq_count_eps = iq_count + eps * (iq_count == 0)
iq_score = torch.div(iq_sum, iq_count_eps)
return iq_score, iq_count
def _update_iq_score_info(self, cat_id, cur_gt_roi_feat):
cur_gt_roi_feat = cur_gt_roi_feat.view(-1, 256, 7, 7)
# update the iq_score queue and corresponding dict info
device_dir = str(cur_gt_roi_feat.device.index)
cur_gt_save_pth = os.path.join(
self.con_queue_dir, device_dir, str(cat_id) + '.pt')
if os.path.exists(cur_gt_save_pth):
cur_pt = torch.load(cur_gt_save_pth).view(-1, 256, 7, 7)
os.remove(cur_gt_save_pth)
cur_gt_roi_feat = torch.cat(
[cur_pt.to(cur_gt_roi_feat.device), cur_gt_roi_feat], dim=0)
cur_gt_roi_feat = cur_gt_roi_feat.view(-1, 256, 7, 7)
dup_len = cur_gt_roi_feat.size(0) > int(self.num_con_queue // self.num_gpus)
if dup_len > 0:
cur_gt_roi_feat = cur_gt_roi_feat[-dup_len, ...]
torch.save(
cur_gt_roi_feat, cur_gt_save_pth, _use_new_zipfile_serialization=False)
def _load_hq_roi_feats(self, roi_feats, gt_labels, cat_ids):
device_id = str(gt_labels.device.index) # current GPU id
with torch.no_grad():
hq_feats, hq_labels = [], []
for cat_id in range(self.num_classes):
if cat_id not in cat_ids:
continue
cur_cat_feat_pth = os.path.join(
self.con_queue_dir, device_id, str(cat_id) + '.pt')
cur_cat_feat = torch.load(cur_cat_feat_pth) \
if os.path.exists(cur_cat_feat_pth) \
else roi_feats.new_empty(0)
cur_cat_roi_feats = cur_cat_feat.to(roi_feats.device).view(-1, 256, 7, 7)
cur_hq_labels = cat_id * gt_labels.new_ones(
cur_cat_roi_feats.size(0)).to(gt_labels.device)
hq_feats.append(cur_cat_roi_feats)
hq_labels.append(cur_hq_labels)
hq_feats = torch.as_tensor(
torch.cat(hq_feats, dim=0),
dtype=roi_feats.dtype).view(-1, 256, 7, 7)
hq_labels = torch.as_tensor(
torch.cat(hq_labels, dim=-1), dtype=gt_labels.dtype)
return hq_feats, hq_labels
def _bbox_forward_train(self, x, assign_results, sampling_results,
gt_bboxes, gt_labels, img_metas):
"""Run forward function and calculate loss for box head in training."""
rois = bbox2roi([res.bboxes for res in sampling_results])
bbox_results = self._bbox_forward(x, rois)
bbox_targets = self.bbox_head.get_targets(sampling_results, gt_bboxes,
gt_labels, self.train_cfg)
loss_bbox = self.bbox_head.loss(bbox_results['cls_score'],
bbox_results['bbox_pred'], rois,
*bbox_targets)
num_proposals = [torch.sum(rois[:, 0] == i) for i in range(len(img_metas))]
cls_scores = bbox_results['cls_score'].clone().split(num_proposals)
bbox_feats = bbox_results['bbox_feats'].clone().split(num_proposals)
comp_feats = bbox_results['comp_feats'].clone().split(num_proposals) # [bs, num_proposals, 256, 1, 1]
proposal_labels = bbox_targets[0].clone().split(num_proposals)
con_losses = cls_scores[0].new_zeros(1)
for i in range(len(sampling_results)):
num_gts = len(gt_labels[i])
cat_ids = list(set(sampling_results[i].pos_gt_labels.tolist()))
cur_sample_num = min(sampling_results[i].neg_inds.size(0), self.con_sample_num)
if num_gts == 0:
contrast_loss = cls_scores[i].new_zeros(1)
con_losses = con_losses + contrast_loss
continue
iq_scores, pro_counts = self._ins_quality_assess(
cls_scores[i],
assign_results[i],
sampling_results[i])
hq_feats, hq_labels = self._load_hq_roi_feats(bbox_feats[i], gt_labels[i], cat_ids)
with torch.no_grad():
for conv in self.comp_convs:
hq_feats = conv(hq_feats) # [num_proposals, 256, 1, 1]
con_roi_feats = torch.cat([comp_feats[i], hq_feats], dim=0) # [num_proposals + num_hq, 256, 1, 1]
hq_inds = torch.nonzero((iq_scores >= self.hq_score) & \
(pro_counts >= self.hq_pro_counts_thr),
as_tuple=False).view(-1) # (N, )
if len(hq_inds) == 0: # no high-quality gt in current image
aug_gt_ind = -1 * torch.ones(con_roi_feats.size(0))
aug_num_per_hq_gt = 0
aug_hq_gt_bboxes = gt_bboxes[i].new_empty(0)
aug_gt_labels = gt_labels[i].new_empty(0)
else:
hq_gt_bboxes = sampling_results[i].pos_gt_bboxes[hq_inds]
img_size = img_metas[i]['img_shape'][0] # use img_w only since img_w == img_h
aug_hq_gt_bboxes, aug_num_per_hq_gt = \
self._aug_hq_gt_bboxes(hq_gt_bboxes, img_size)
aug_hq_gt_rois = bbox2roi([aug_hq_gt_bboxes])
aug_hq_gt_roi_feats = self.aug_roi_extractor(x, aug_hq_gt_rois)
with torch.no_grad():
for conv in self.comp_convs:
aug_hq_gt_roi_feats = conv(aug_hq_gt_roi_feats)
aug_gt_ind = hq_inds.view(-1, 1).repeat(1, aug_num_per_hq_gt).view(1, -1).squeeze(0)
aug_gt_ind = torch.cat(
[-1 * aug_gt_ind.new_ones(con_roi_feats.size(0)), aug_gt_ind], dim=-1)
aug_gt_labels = sampling_results[i].pos_gt_labels[hq_inds].view(
-1, 1).repeat(1, aug_num_per_hq_gt).view(1, -1).squeeze(0)
con_roi_feats = torch.cat([con_roi_feats, aug_hq_gt_roi_feats], dim=0) # [num_proposals + num_hq + num_hq_aug, 256, 1, 1]
iq_signs, ex_pos_nums = self._get_gt_quality(
iq_scores, aug_num_per_hq_gt, gt_labels[i], cur_sample_num)
is_hq = torch.cat(
[gt_labels[i].new_zeros(num_proposals[i]),
torch.ones_like(hq_labels),
-gt_labels[i].new_ones(aug_hq_gt_bboxes.size(0))], dim=-1)
roi_labels = torch.cat(
[proposal_labels[i], hq_labels, aug_gt_labels], dim=-1)
assert roi_labels.size(0) == con_roi_feats.size(0)
# for dense ground-truth situation, only a part of gt will be processed,
# which resembles the way of gt being handled in bbox_sampler
num_actual_gts = sampling_results[i].pos_is_gt.sum()
pos_assigned_gt_inds = sampling_results[i].pos_assigned_gt_inds
pos_is_gt = sampling_results[i].pos_is_gt.bool()
pos_assigned_actual_gt_inds = pos_assigned_gt_inds[pos_is_gt]
iq_scores = iq_scores[pos_assigned_actual_gt_inds]
iq_signs = iq_signs[pos_assigned_actual_gt_inds]
ex_pos_nums = ex_pos_nums[pos_assigned_actual_gt_inds]
labels = gt_labels[i][pos_assigned_actual_gt_inds]
sample_inds, pos_signs = self._sample(
iq_signs, ex_pos_nums, labels, roi_labels, is_hq, aug_gt_ind, cur_sample_num)
# anchor_feature: (num_gts, 256, 7, 7)
# contrast_feature: (num_gts, self.con_sample_num, 256, 7, 7)
anchor_feature = con_roi_feats[:num_actual_gts]
contrast_feature = con_roi_feats[sample_inds]
assert anchor_feature.size(0) == contrast_feature.size(0)
iq_loss_weights = torch.ones_like(iq_scores)
for j, weight in enumerate(self.iq_loss_weights):
cur_signs = torch.nonzero(iq_signs == j).view(-1)
iq_loss_weights[cur_signs] = weight * iq_loss_weights[cur_signs]
loss = self.contrast_forward(anchor_feature, contrast_feature,
pos_signs, iq_loss_weights)
contrast_loss = self.contrast_loss_weights * loss
con_losses = con_losses + contrast_loss
# save high-quality features at last
# for dense ground-truth situation
pro_counts = pro_counts[pos_assigned_actual_gt_inds]
hq_inds = torch.nonzero((iq_scores >= self.hq_score) & \
(pro_counts >= self.hq_pro_counts_thr),
as_tuple=False).view(-1) # (N, )
# high-quality proposals: high instance quality scores and
# sufficient numbers of proposals
if len(hq_inds) > 0:
hq_scores, hq_pro_counts = \
iq_scores[hq_inds], pro_counts[hq_inds]
for hq_score, hq_pro_count, hq_gt_ind in \
zip(hq_scores, hq_pro_counts, hq_inds):
cur_gt_cat_id = sampling_results[i].pos_gt_labels[hq_gt_ind]
cur_gt_roi_feat = bbox_feats[i][hq_gt_ind, :, :, :].clone()
self._update_iq_score_info(cur_gt_cat_id.item(), cur_gt_roi_feat)
if len(con_losses) > 0:
con_loss = con_losses / len(assign_results)
loss_bbox.update(loss_con=con_loss)
bbox_results.update(loss_bbox=loss_bbox)
return bbox_results
def contrast_forward(self, anchor_feature, contrast_feature,
pos_signs, loss_weights, eps=1e-6):
"""
Args:
anchor_feature: ground-truth roi features in a single image
(num_gts, 256, 1, 1)
contrast_feature: pos/neg rois features fro training
(num_gts, self.con_sample_num, 256, 1, 1)
pos_signs: indicate whether the sample pos/neg (1/0)
(num_gts, self.con_sample_num)
loss_weights: loss weights of each gt (num_gts, )
"""
anchor_feature = anchor_feature.view(anchor_feature.size()[:-2]) # [num_gts, 256]
contrast_feature = contrast_feature.view(contrast_feature.size()[:-2]) # [num_gts, self.con_sample_num, 256]
for fc in self.fc_enc:
anchor_feature = self.relu(fc(anchor_feature))
contrast_feature = self.relu(fc(contrast_feature))
anchor_feature = self.fc_proj(anchor_feature)
contrast_feature = self.fc_proj(contrast_feature)
anchor_feats = F.normalize(anchor_feature, dim=-1) # (num_gts, 128)
contrast_feats = F.normalize(contrast_feature, dim=-1) # (num_gts, self.con_sample_num, 128)
sim_logits = torch.div( # (num_gts, self.con_sample_num)
torch.matmul(anchor_feats.unsqueeze(1),
contrast_feats.transpose(2, 1).contiguous()),
self.temperature).squeeze(1)
# for numerical stability
sim_logits_max, _ = torch.max(sim_logits, dim=1, keepdim=True)
logits = sim_logits - sim_logits_max.detach() # (num_gts, self.con_sample_num)
exp_logits = torch.exp(logits)
log_prob = logits - torch.log(exp_logits.sum(1, keepdim=True))
pos_num = pos_signs.sum(dim=1).cuda()
pos_num = pos_num + eps * (pos_num == 0) # avoid dividing by zero
mean_log_prob_pos = -(pos_signs * log_prob).sum(dim=1) / pos_num
weighted_loss = loss_weights * mean_log_prob_pos
loss = weighted_loss.mean()
return loss
def _get_gt_quality(self, iq_scores, aug_num_per_hq_gt, gt_labels, cur_sample_num):
""" low-quality: 0;
mid_qulity: 1;
high-quality: 2;
"""
with torch.no_grad():
iq_signs = torch.zeros_like(iq_scores) # low-quality
iq_signs[iq_scores >= self.lq_score] = 1 # mid-quality
iq_signs[iq_scores >= self.hq_score] = 2 # high-quality
pos_fraction = self.con_sampler_cfg['pos_fraction']
ex_pos_nums = gt_labels.new_ones(iq_scores.size(0))
for val in range(2):
ex_pos_nums[iq_signs == val] = int(cur_sample_num * pos_fraction[val])
ex_pos_nums[iq_signs == 2] = aug_num_per_hq_gt
return iq_signs, ex_pos_nums
def _sample(self, iq_signs, ex_pos_nums, gt_labels, roi_labels,
is_hq, aug_gt_ind, cur_sample_num):
"""
Returns:
sample_inds : indices of pos and neg samples (num_gts, self.con_sample_num)
pos_signs : whether the sample of current index is positive
"""
sample_inds, pos_signs = [], []
for gt_ind in range(len(gt_labels)):
ex_pos_num = ex_pos_nums[gt_ind]
iq_sign = iq_signs[gt_ind]
# sample positives first
if iq_sign == 2:
pos_inds = torch.nonzero(aug_gt_ind == gt_ind, as_tuple=False).view(-1)
else:
can_pos_inds = torch.nonzero(
(is_hq == 1) & (roi_labels == gt_labels[gt_ind]),
as_tuple=False).view(-1)
if len(can_pos_inds) <= ex_pos_num:
pos_inds = can_pos_inds
else:
pos_inds = self._random_choice(can_pos_inds, ex_pos_num)
# sample negatives then
can_neg_inds = torch.nonzero(
(roi_labels != gt_labels[gt_ind]) & (is_hq == 0),
as_tuple=False).view(-1)
neg_inds = self._random_choice(
can_neg_inds, cur_sample_num - len(pos_inds))
sample_inds.append(
torch.cat([pos_inds.cuda(), neg_inds.cuda()], dim=-1).view(1, -1))
pos_signs.append(
torch.cat([torch.ones_like(pos_inds.cuda()),
torch.zeros_like(neg_inds.cuda())], dim=-1).view(1, -1))
sample_inds = torch.cat(sample_inds, dim=0)
pos_signs = torch.cat(pos_signs, dim=0)
return sample_inds, pos_signs
def _random_choice(self, gallery, num):
# fork from RandomSampler
assert len(gallery) >= num
is_tensor = isinstance(gallery, torch.Tensor)
if not is_tensor:
if torch.cuda.is_available():
device = torch.cuda.current_device()
else:
device = 'cpu'
gallery = torch.tensor(gallery, dtype=torch.long, device=device)
perm = torch.randperm(gallery.numel())[:num].to(device=gallery.device)
rand_inds = gallery[perm]
if not is_tensor:
rand_inds = rand_inds.cpu().numpy()
return rand_inds
def _aug_hq_gt_bboxes(self, hq_gt_bboxes, img_w):
with torch.no_grad():
hq_gt_bboxes = hq_gt_bboxes.view(-1, 4)
num_gts = hq_gt_bboxes.size(0)
trans_range, rescale_range = \
self.hq_gt_aug_cfg['trans_range'], self.hq_gt_aug_cfg['rescale_range']
trans_num, rescale_num = \
self.hq_gt_aug_cfg['trans_num'], self.hq_gt_aug_cfg['rescale_num']
trans_ratios = torch.linspace(
trans_range[0], trans_range[1], trans_num).view(-1).cuda()
rescale_ratios = torch.linspace(
rescale_range[0], rescale_range[1], rescale_num).view(-1).cuda()
gt_bboxes = hq_gt_bboxes.unsqueeze(1)
# gt box translation
trans_candi = gt_bboxes.repeat(1, 4 * trans_num, 1) # (num_gts, 4*trans_num, 4)
w = hq_gt_bboxes[:, 3] - hq_gt_bboxes[:, 1]
h = hq_gt_bboxes[:, 2] - hq_gt_bboxes[:, 0]
wh = torch.cat([w.view(-1, 1), h.view(-1, 1)], dim=1).unsqueeze(1) # (num_gts, 1, 2)
inter_mat = torch.cat(
[torch.eye(2), torch.eye(2) * (-1)], dim=0).cuda() # (4, 2)
wh_mat = wh * inter_mat # (num_gts, 4, 2)
scaled_wh = torch.cat( # (num_gts, 4*trans_num, 2)
[r * wh_mat for r in trans_ratios], dim=1)
trans_wh = scaled_wh.repeat(1, 1, 2) # (num_gts, 4*trans_num, 4)
trans_gt_bboxes = trans_candi + trans_wh # (num_gts, 4*trans_num, 4)
trans_gt_bboxes = torch.clamp(trans_gt_bboxes, 0, img_w)
# gt box rescale
rescaled_gt_bboxes = self.rescale_gt_bboxes(
hq_gt_bboxes, rescale_ratios) # (num_gts, rescale_num, 4)
rescaled_gt_bboxes = torch.clamp(rescaled_gt_bboxes, 0, img_w)
aug_gt_bboxes = []
for i in range(num_gts):
aug_gt_bboxes.append(
torch.cat([trans_gt_bboxes[i], rescaled_gt_bboxes[i]],
dim=0))
aug_gt_bboxes = torch.cat(aug_gt_bboxes, dim=0) # (num_gts, 4*trans_num+rescale_num, 4)
aug_num_per_hq_gt = 4 * trans_num + rescale_num
return aug_gt_bboxes, aug_num_per_hq_gt
def rescale_gt_bboxes(self, gt_bboxes, scale_factors):
cx = (gt_bboxes[:, 0] + gt_bboxes[:, 2]) * 0.5
cy = (gt_bboxes[:, 1] + gt_bboxes[:, 3]) * 0.5
w = gt_bboxes[:, 2] - gt_bboxes[:, 0]
h = gt_bboxes[:, 3] - gt_bboxes[:, 1]
rescaled_gt_bboxes = []
for scale_factor in scale_factors:
new_w = w * scale_factor
new_h = h * scale_factor
x1 = cx - new_w * 0.5
x2 = cx + new_w * 0.5
y1 = cy - new_h * 0.5
y2 = cy + new_h * 0.5
rescaled_gt_bboxes.append(
torch.stack((x1, y1, x2, y2), dim=-1))
rescaled_gt_bboxes = torch.cat(
rescaled_gt_bboxes, dim=0).view(gt_bboxes.size(0), -1, 4)
return rescaled_gt_bboxes
def _mask_forward_train(self, x, sampling_results, bbox_feats, gt_masks,
img_metas):
"""Run forward function and calculate loss for mask head in
training."""
if not self.share_roi_extractor:
pos_rois = bbox2roi([res.pos_bboxes for res in sampling_results])
mask_results = self._mask_forward(x, pos_rois)
else:
pos_inds = []
device = bbox_feats.device
for res in sampling_results:
pos_inds.append(
torch.ones(
res.pos_bboxes.shape[0],
device=device,
dtype=torch.uint8))
pos_inds.append(
torch.zeros(
res.neg_bboxes.shape[0],
device=device,
dtype=torch.uint8))
pos_inds = torch.cat(pos_inds)
mask_results = self._mask_forward(
x, pos_inds=pos_inds, bbox_feats=bbox_feats)
mask_targets = self.mask_head.get_targets(sampling_results, gt_masks,
self.train_cfg)
pos_labels = torch.cat([res.pos_gt_labels for res in sampling_results])
loss_mask = self.mask_head.loss(mask_results['mask_pred'],
mask_targets, pos_labels)
mask_results.update(loss_mask=loss_mask, mask_targets=mask_targets)
return mask_results
def _mask_forward(self, x, rois=None, pos_inds=None, bbox_feats=None):
"""Mask head forward function used in both training and testing."""
assert ((rois is not None) ^
(pos_inds is not None and bbox_feats is not None))
if rois is not None:
mask_feats = self.mask_roi_extractor(
x[:self.mask_roi_extractor.num_inputs], rois)
if self.with_shared_head:
mask_feats = self.shared_head(mask_feats)
else:
assert bbox_feats is not None
mask_feats = bbox_feats[pos_inds]
mask_pred = self.mask_head(mask_feats)
mask_results = dict(mask_pred=mask_pred, mask_feats=mask_feats)
return mask_results
async def async_simple_test(self,
x,
proposal_list,
img_metas,
proposals=None,
rescale=False):
"""Async test without augmentation."""
assert self.with_bbox, 'Bbox head must be implemented.'
det_bboxes, det_labels = await self.async_test_bboxes(
x, img_metas, proposal_list, self.test_cfg, rescale=rescale)
bbox_results = bbox2result(det_bboxes, det_labels,
self.bbox_head.num_classes)
if not self.with_mask:
return bbox_results
else:
segm_results = await self.async_test_mask(
x,
img_metas,
det_bboxes,
det_labels,
rescale=rescale,
mask_test_cfg=self.test_cfg.get('mask'))
return bbox_results, segm_results
def simple_test(self,
x,
proposal_list,
img_metas,
# gt_bboxes, gt_labels,
proposals=None,
rescale=False):
"""Test without augmentation.
Args:
x (tuple[Tensor]): Features from upstream network. Each
has shape (batch_size, c, h, w).
proposal_list (list(Tensor)): Proposals from rpn head.
Each has shape (num_proposals, 5), last dimension
5 represent (x1, y1, x2, y2, score).
img_metas (list[dict]): Meta information of images.
rescale (bool): Whether to rescale the results to
the original image. Default: True.
Returns:
list[list[np.ndarray]] or list[tuple]: When no mask branch,
it is bbox results of each image and classes with type
`list[list[np.ndarray]]`. The outer list
corresponds to each image. The inner list
corresponds to each class. When the model has mask branch,
it contains bbox results and mask results.
The outer list corresponds to each image, and first element
of tuple is bbox results, second element is mask results.
"""
assert self.with_bbox, 'Bbox head must be implemented.'
det_bboxes, det_labels = self.simple_test_bboxes(
x, img_metas, proposal_list, self.test_cfg, rescale=rescale)
bbox_results = [
bbox2result(det_bboxes[i], det_labels[i],
self.bbox_head.num_classes)
for i in range(len(det_bboxes))
]
if not self.with_mask:
return bbox_results
else:
segm_results = self.simple_test_mask(
x, img_metas, det_bboxes, det_labels, rescale=rescale)
return list(zip(bbox_results, segm_results))
def aug_test(self, x, proposal_list, img_metas, rescale=False):
"""Test with augmentations.
If rescale is False, then returned bboxes and masks will fit the scale
of imgs[0].
"""
det_bboxes, det_labels = self.aug_test_bboxes(x, img_metas,
proposal_list,
self.test_cfg)
if rescale:
_det_bboxes = det_bboxes
else:
_det_bboxes = det_bboxes.clone()
_det_bboxes[:, :4] *= det_bboxes.new_tensor(
img_metas[0][0]['scale_factor'])
bbox_results = bbox2result(_det_bboxes, det_labels,
self.bbox_head.num_classes)
# det_bboxes always keep the original scale
if self.with_mask:
segm_results = self.aug_test_mask(x, img_metas, det_bboxes,
det_labels)
return [(bbox_results, segm_results)]
else:
return [bbox_results]
def onnx_export(self, x, proposals, img_metas, rescale=False):
"""Test without augmentation."""
assert self.with_bbox, 'Bbox head must be implemented.'
det_bboxes, det_labels = self.bbox_onnx_export(
x, img_metas, proposals, self.test_cfg, rescale=rescale)
if not self.with_mask:
return det_bboxes, det_labels
else:
segm_results = self.mask_onnx_export(
x, img_metas, det_bboxes, det_labels, rescale=rescale)
return det_bboxes, det_labels, segm_results
def mask_onnx_export(self, x, img_metas, det_bboxes, det_labels, **kwargs):
"""Export mask branch to onnx which supports batch inference.
Args:
x (tuple[Tensor]): Feature maps of all scale level.
img_metas (list[dict]): Image meta info.
det_bboxes (Tensor): Bboxes and corresponding scores.
has shape [N, num_bboxes, 5].
det_labels (Tensor): class labels of
shape [N, num_bboxes].
Returns:
Tensor: The segmentation results of shape [N, num_bboxes,
image_height, image_width].
"""
# image shapes of images in the batch
if all(det_bbox.shape[0] == 0 for det_bbox in det_bboxes):
raise RuntimeError('[ONNX Error] Can not record MaskHead '
'as it has not been executed this time')
batch_size = det_bboxes.size(0)
# if det_bboxes is rescaled to the original image size, we need to
# rescale it back to the testing scale to obtain RoIs.
det_bboxes = det_bboxes[..., :4]
batch_index = torch.arange(
det_bboxes.size(0), device=det_bboxes.device).float().view(
-1, 1, 1).expand(det_bboxes.size(0), det_bboxes.size(1), 1)
mask_rois = torch.cat([batch_index, det_bboxes], dim=-1)
mask_rois = mask_rois.view(-1, 5)
mask_results = self._mask_forward(x, mask_rois)
mask_pred = mask_results['mask_pred']
max_shape = img_metas[0]['img_shape_for_onnx']
num_det = det_bboxes.shape[1]
det_bboxes = det_bboxes.reshape(-1, 4)
det_labels = det_labels.reshape(-1)
segm_results = self.mask_head.onnx_export(mask_pred, det_bboxes,
det_labels, self.test_cfg,
max_shape)
segm_results = segm_results.reshape(batch_size, num_det, max_shape[0],
max_shape[1])
return segm_results
def bbox_onnx_export(self, x, img_metas, proposals, rcnn_test_cfg,
**kwargs):
"""Export bbox branch to onnx which supports batch inference.
Args:
x (tuple[Tensor]): Feature maps of all scale level.
img_metas (list[dict]): Image meta info.
proposals (Tensor): Region proposals with
batch dimension, has shape [N, num_bboxes, 5].
rcnn_test_cfg (obj:`ConfigDict`): `test_cfg` of R-CNN.
Returns:
tuple[Tensor, Tensor]: bboxes of shape [N, num_bboxes, 5]
and class labels of shape [N, num_bboxes].
"""
# get origin input shape to support onnx dynamic input shape
assert len(
img_metas
) == 1, 'Only support one input image while in exporting to ONNX'
img_shapes = img_metas[0]['img_shape_for_onnx']
rois = proposals
batch_index = torch.arange(
rois.size(0), device=rois.device).float().view(-1, 1, 1).expand(
rois.size(0), rois.size(1), 1)
rois = torch.cat([batch_index, rois[..., :4]], dim=-1)
batch_size = rois.shape[0]
num_proposals_per_img = rois.shape[1]
# Eliminate the batch dimension
rois = rois.view(-1, 5)
bbox_results = self._bbox_forward(x, rois)
cls_score = bbox_results['cls_score']
bbox_pred = bbox_results['bbox_pred']
# Recover the batch dimension
rois = rois.reshape(batch_size, num_proposals_per_img, rois.size(-1))
cls_score = cls_score.reshape(batch_size, num_proposals_per_img,
cls_score.size(-1))
bbox_pred = bbox_pred.reshape(batch_size, num_proposals_per_img,
bbox_pred.size(-1))
det_bboxes, det_labels = self.bbox_head.onnx_export(
rois, cls_score, bbox_pred, img_shapes, cfg=rcnn_test_cfg)
return det_bboxes, det_labels
Q.E.D.